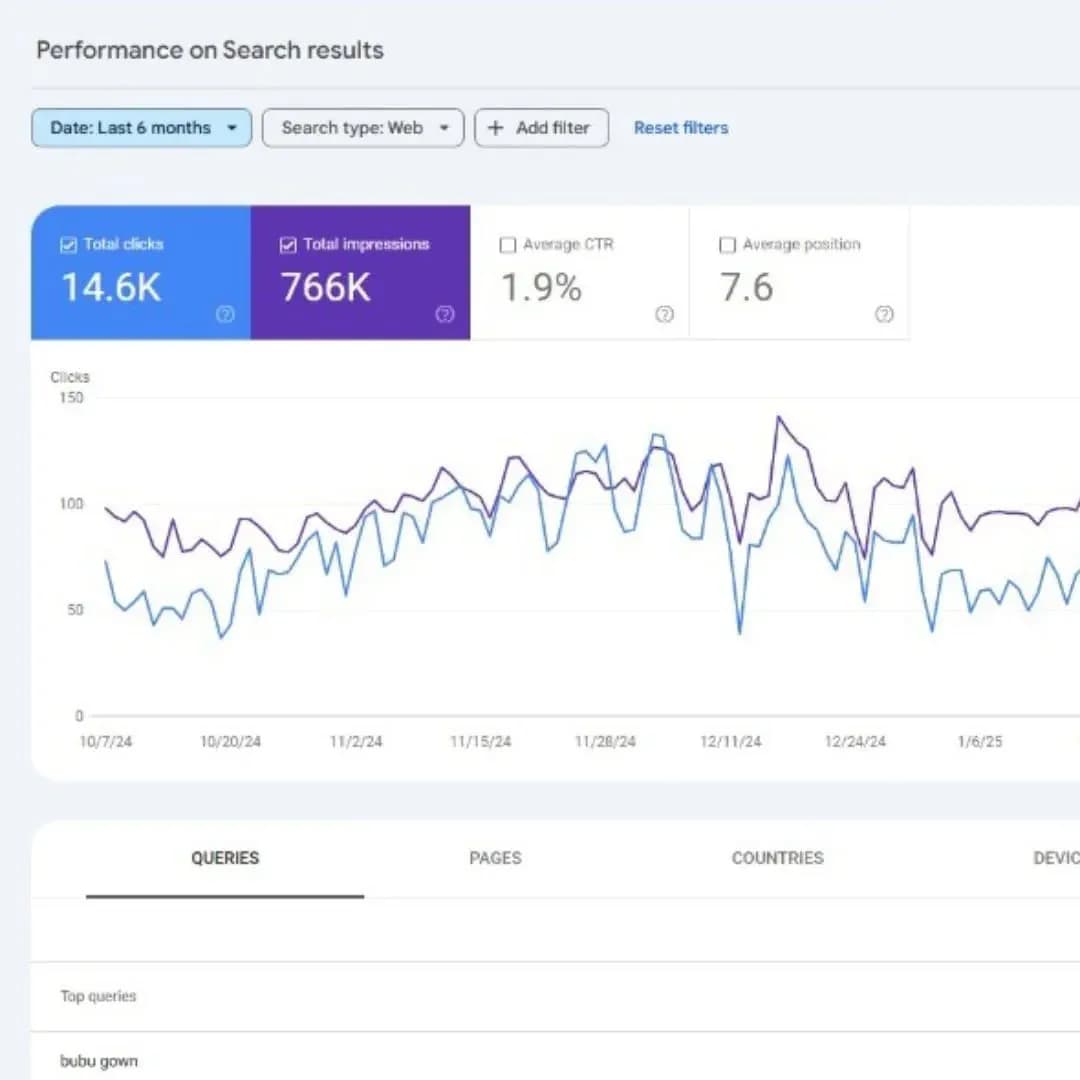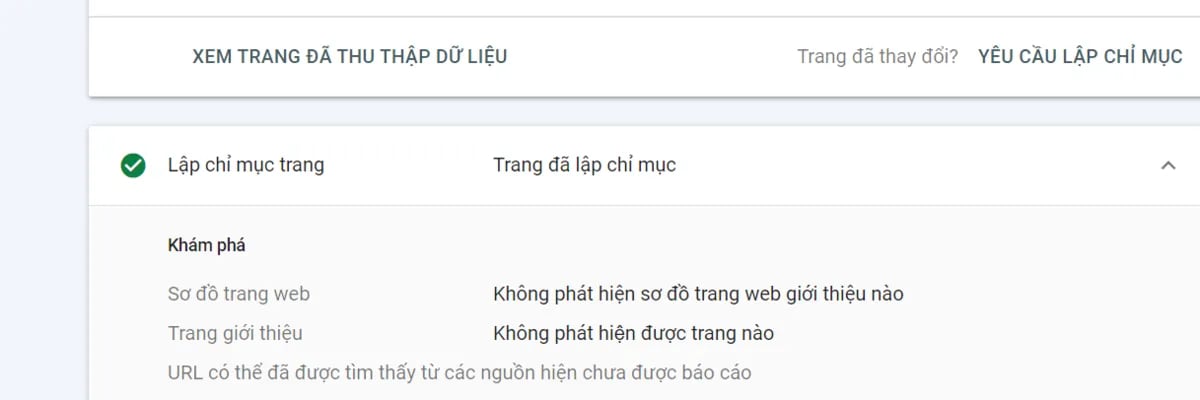
Sự hiện diện của một trang web trên công cụ tìm kiếm Google không còn là một tiến trình ngẫu nhiên hay mặc định trong kỷ nguyên số hiện đại. Đối với các chuyên gia tối ưu hóa công cụ tìm kiếm (SEO) và quản trị viên hệ thống, việc đối mặt với báo cáo trạng thái trong Google Search Console (GSC) là một phần tất yếu của công việc quản trị. Trong số các thông báo gây ra nhiều sự bối rối nhất, "Discovered – currently not indexed" (Đã phát hiện – hiện chưa được lập chỉ mục) nổi lên như một thách thức kỹ thuật phức tạp, phản ánh sự giao thoa giữa hiệu suất hạ tầng, ngân sách thu thập dữ liệu và đánh giá giá trị nội dung của thuật toán. Báo cáo này từ Tấn Phát Digital sẽ đi sâu vào phân tích bản chất hệ thống của lỗi này, bóc tách các tầng nguyên nhân từ hạ tầng đến chiến lược nội dung, đồng thời cung cấp một khung giải pháp toàn diện để khắc phục triệt để và bền vững.
Khung Lý thuyết và Phân loại Trạng thái Lập chỉ mục
Để hiểu rõ lỗi "Discovered – currently not indexed", trước hết cần đặt nó vào trong chuỗi cung ứng dữ liệu của Google. Tiến trình lập chỉ mục của Google trải qua ba giai đoạn chính: Khám phá (Discovery), Thu thập dữ liệu (Crawling) và Lập chỉ mục (Indexing). Trạng thái "Discovered" xuất hiện khi Google đã hoàn thành giai đoạn đầu tiên nhưng lại quyết định tạm dừng hoặc trì hoãn giai đoạn thứ hai. Điều này có nghĩa là URL đã nằm trong hàng đợi thu thập dữ liệu của Googlebot, nhưng hệ thống chưa thực hiện việc tải xuống mã nguồn hay phân tích nội dung.
Sự phân tách kỹ thuật giữa "Discovered" và "Crawled"
Một trong những sai lầm phổ biến nhất của các nhà quản trị web là đánh đồng trạng thái "Discovered – currently not indexed" với "Crawled – currently not indexed". Sự khác biệt giữa hai trạng thái này không chỉ nằm ở thuật ngữ mà còn ở mức độ nghiêm trọng và bản chất của vấn đề mà trang web đang gặp phải. Dưới đây là các tiêu chí so sánh chi tiết:
Trạng thái: Discovered – currently not indexed
Hành động của Googlebot: Chưa truy cập trang, chưa tải HTML.
Vấn đề cốt lõi: Thường liên quan đến ngân sách thu thập, ưu tiên hệ thống hoặc hiệu suất máy chủ.
Ngày thu thập gần nhất: Trống (không có dữ liệu).
Chiến lược khắc phục: Tối ưu hóa tốc độ máy chủ, cấu trúc liên kết và tín hiệu ưu tiên.
Trạng thái: Crawled – currently not indexed
Hành động của Googlebot: Đã truy cập, tải trang và kết xuất (render) thành công.
Vấn đề cốt lõi: Thường liên quan đến chất lượng nội dung, giá trị độc nhất hoặc đáp ứng ý định tìm kiếm.
Ngày thu thập gần nhất: Có ghi nhận thời gian thu thập cụ thể.
Chiến lược khắc phục: Nâng cấp chất lượng nội dung, loại bỏ nội dung mỏng hoặc trùng lặp.
Phân tích sâu hơn chỉ ra rằng nếu một trang rơi vào trạng thái "Crawled", Google đã đánh giá nội dung đó và quyết định nó không đủ tiêu chuẩn để hiển thị cho người dùng. Ngược lại, với trạng thái "Discovered", Google thậm chí còn chưa bắt đầu quy trình đánh giá chất lượng chi tiết, cho thấy một rào cản mang tính hệ thống ở cấp độ tiếp cận dữ liệu.
Phân tích Nguyên nhân Hạ tầng và Hiệu suất Máy chủ
Google luôn nỗ lực để trở thành một "công dân tốt" trên mạng Internet bằng cách không làm gián đoạn hoạt động bình thường của các trang web mà nó thu thập dữ liệu. Khi Googlebot phát hiện một lượng lớn URL mới nhưng nhận thấy máy chủ đang có dấu hiệu phản hồi chậm hoặc không ổn định, nó sẽ tự động điều chỉnh giảm tốc độ thu thập dữ liệu để tránh gây ra tình trạng quá tải hoặc sập hệ thống (server crash).
Cơ chế tự bảo vệ và quá tải máy chủ
Dựa trên kinh nghiệm của Tấn Phát Digital, hiện tượng máy chủ bị quá tải (overloaded server) là nguyên nhân hàng đầu khiến các URL bị đẩy vào trạng thái "Đã phát hiện nhưng chưa thu thập". Khi Googlebot thực hiện các yêu cầu HTTP đồng thời, nếu thời gian phản hồi của máy chủ (Time to First Byte - TTFB) tăng vọt vượt ngưỡng cho phép, thuật toán sẽ tự động đưa các URL còn lại vào hàng đợi chờ. Điều này tạo ra một "điểm nghẽn" kỹ thuật: Google biết nội dung mới tồn tại nhưng không dám truy cập vì lo ngại về tính toàn vẹn của hạ tầng trang web.
Các lỗi kết nối và trạng thái máy chủ (Host Status)
Báo cáo "Crawl Stats" trong GSC cung cấp những chỉ dấu quan trọng về sức khỏe của máy chủ. Các vấn đề về Host Status bao gồm:
DNS resolution: Google không thể tìm thấy địa chỉ IP của tên miền. Điều này ngăn chặn hoàn toàn việc thu thập dữ liệu ngay từ bước đầu.
Server connectivity: Kết nối bị từ chối hoặc bị ngắt quãng giữa chừng. Lỗi này gây ra các mã phản hồi 5xx, khiến Googlebot ngay lập tức rút lui để bảo vệ máy chủ.
Robots.txt fetching: Không thể đọc tệp quy tắc robots.txt. Google sẽ ngừng thu thập toàn bộ trang web cho đến khi tệp này khả dụng.
Nếu trang web gặp phải lỗi DNS_PROBE_FINISHED_NXDOMAIN, điều này có nghĩa là hệ thống tên miền không thể phân giải URL thành địa chỉ IP. Đây là một rào cản vật lý khiến Googlebot không thể "nhìn thấy" máy chủ, từ đó các trang web mới chỉ dừng lại ở mức độ "phát hiện" thông qua sitemap mà không thể tiến xa hơn.
Ngân sách thu thập dữ liệu (Crawl Budget) và Chiến lược Phân bổ Tài nguyên
Đối với các hệ thống website quy mô lớn (thường trên 10.000 trang), ngân sách thu thập dữ liệu không còn là một khái niệm lý thuyết mà là một tài nguyên hữu hạn cần được quản trị nghiêm ngặt. Googlebot phân bổ một lượng tài nguyên nhất định cho mỗi trang web dựa trên hai yếu tố: Giới hạn tốc độ thu thập (Crawl Rate Limit) và Nhu cầu thu thập (Crawl Demand).
Sự lãng phí ngân sách trên nội dung kém chất lượng
Một nguyên nhân sâu xa của lỗi "Discovered – currently not indexed" là sự lãng phí ngân sách thu thập dữ liệu vào các khu vực không quan trọng của trang web. Nếu một trang web chứa hàng nghìn trang được tạo ra bởi các bộ lọc sản phẩm, tham số tìm kiếm hoặc nội dung trùng lặp, Googlebot có thể dành toàn bộ tài nguyên để thu thập các trang này và không còn "ngân sách" để ghé thăm các bài viết mới hoặc sản phẩm mới.
Phân tích dữ liệu thực tế cho thấy, nếu một trang web có tỷ lệ URL có ích (indexable) quá thấp so với tổng số URL mà Googlebot khám phá được, Google sẽ nhận diện trang web đó là "nặng nề" và kém hiệu quả. Khi đó, Googlebot sẽ giảm dần tần suất ghé thăm, dẫn đến tình trạng hàng dài URL mới bị kẹt ở trạng thái "Discovered".
Mối tương quan giữa thẩm quyền trang web và nhu cầu thu thập
Nhu cầu thu thập dữ liệu của Google tỉ lệ thuận với độ tin cậy và thẩm quyền của trang web (Site Authority). Các trang web mới thành lập hoặc các trang web có hồ sơ liên kết (backlink profile) yếu thường có nhu cầu thu thập thấp. Tấn Phát Digital nhận định rằng Google không cảm thấy sự cấp thiết phải cập nhật các nội dung từ những nguồn này vì chúng chưa chứng minh được tầm ảnh hưởng đối với người dùng.
Vai trò của Cấu trúc Liên kết Nội bộ và Tín hiệu Khám phá
Googlebot khám phá các trang web chủ yếu thông qua các liên kết. Nếu một trang web chỉ tồn tại trong sơ đồ trang web (XML Sitemap) mà không có các liên kết nội bộ trỏ đến, Google sẽ coi đó là một trang "mồ côi" (orphan page) và gán cho nó một mức độ ưu tiên cực thấp.
Độ sâu thu thập và phân cấp trang web
Cấu trúc trang web lộn xộn hoặc quá sâu (deep click depth) là rào cản lớn đối với quá trình lập chỉ mục. Theo các tiêu chuẩn SEO kỹ thuật mà Tấn Phát Digital áp dụng, một URL nên được truy cập trong vòng không quá 3 lượt nhấp chuột từ trang chủ. Khi một trang nằm quá sâu, Googlebot có thể "phát hiện" ra nó thông qua sitemap nhưng lại không đủ động lực để thực hiện hành trình thu thập dữ liệu phức tạp đến trang đó.
Tín hiệu từ Anchor Text và Vị trí Liên kết
Vị trí của liên kết trên trang cũng đóng vai trò như một tín hiệu ưu tiên. Các liên kết nằm trong thanh điều hướng chính (Navigation Bar), chân trang (Footer) hoặc trong nội dung chính của những trang có lưu lượng truy cập cao sẽ thúc đẩy Googlebot thu thập dữ liệu nhanh hơn. Việc sử dụng Anchor Text mô tả rõ ràng giúp Google hiểu được ngữ cảnh và giá trị của trang đích, từ đó tăng khả năng được ưu tiên thu thập.
Chất lượng Nội dung và Hệ thống Dự đoán của Thuật toán
Trong những năm gần đây, Google đã tích hợp các mô hình học máy để dự đoán chất lượng của một trang web ngay cả trước khi nó được thu thập dữ liệu. Nếu một hệ thống website có tiền sử chứa nhiều nội dung mỏng (thin content), nội dung sao chép hoặc nội dung được tạo bằng AI kém chất lượng, thuật toán sẽ tự động gán nhãn "ưu tiên thấp" cho mọi URL mới phát hiện được.
Chất lượng mang tính toàn trang (Site-wide Quality Issues)
Lỗi "Discovered – currently not indexed" thường không phản ánh vấn đề của riêng URL đó, mà là sự phản hồi của Google đối với chất lượng tổng thể của toàn bộ website. Đại diện Google, John Mueller, đã từng nhấn mạnh rằng nếu một trang web có quá nhiều nội dung không mang lại giá trị, hệ thống sẽ trở nên "thận trọng" hơn và hạn chế việc thu thập các trang mới.
Nội dung trùng lặp và xung đột Canonical
Khi Google phát hiện nhiều URL có cấu trúc khác nhau nhưng dẫn đến cùng một nội dung, nó sẽ chỉ chọn một bản duy nhất để lập chỉ mục. Các URL còn lại sẽ bị đẩy vào trạng thái bị loại trừ. Tấn Phát Digital khuyên bạn nên kiểm tra kỹ thẻ canonical để cung cấp tín hiệu rõ ràng cho Google.
Quy trình Chẩn đoán và Khắc phục Triệt để từ Tấn Phát Digital
Việc khắc phục lỗi này đòi hỏi một phương pháp tiếp cận đa tầng, kết hợp giữa sửa lỗi kỹ thuật tức thời và tối ưu hóa chiến lược dài hạn.
Giai đoạn 1: Kiểm tra Kỹ thuật và Loại trừ Rào cản
Bước đầu tiên là phải đảm bảo không có bất kỳ lệnh cấm nào ngăn cản Googlebot một cách trực tiếp thông qua các phương pháp sau:
URL Inspection Tool: Nhập URL bị ảnh hưởng và chạy "Live Test" để xác định xem trang có đang phản hồi 200 OK không.
Kiểm tra Robots.txt: Rà soát các quy tắc Disallow để đảm bảo các thư mục quan trọng không bị chặn vô tình.
Meta Robots Tags: Tìm kiếm thẻ noindex trong mã nguồn HTML và loại bỏ chúng.
X-Robots-Tag: Kiểm tra tiêu đề phản hồi HTTP (HTTP Headers) để phát hiện các lệnh chặn ở cấp độ máy chủ hoặc CDN.
Giai đoạn 2: Tối ưu hóa Hiệu suất và Ngân sách Thu thập
Nếu không có rào cản kỹ thuật trực tiếp, trọng tâm cần chuyển sang việc cải thiện khả năng thu thập của hệ thống:
Dịch vụ thiết kế website chuẩn SEO: Việc lựa chọn một đối tác thiết kế website chuyên nghiệp là bước đi nền tảng; một cấu trúc mã nguồn (code) không đạt chuẩn hoặc sắp xếp mục lục không khoa học sẽ trực tiếp khiến Googlebot gặp khó khăn và index chậm. Tấn Phát Digital cung cấp giải pháp thiết kế website tối ưu hóa từ mã nguồn, đảm bảo hệ thống phân mục rõ ràng, thân thiện với thuật toán và người dùng ngay từ giai đoạn khởi tạo.
Nâng cấp hạ tầng máy chủ: Đảm bảo máy chủ có đủ tài nguyên (CPU, RAM) để xử lý các yêu cầu từ bot mà không làm tăng TTFB.
Giảm tải tài nguyên nặng: Sử dụng robots.txt để chặn Googlebot tải các tệp script hoặc hình ảnh trang trí quá lớn không cần thiết.
Xử lý chuỗi chuyển hướng: Loại bỏ các chuỗi chuyển hướng hoặc vòng lặp chuyển hướng để tiết kiệm ngân sách thu thập.
Nén và tối ưu hóa hình ảnh: Đảm bảo dung lượng hình ảnh dưới 100kb và sử dụng định dạng hiện đại như WebP.
Giai đoạn 3: Tăng cường Tín hiệu Ưu tiên và Thẩm quyền
Để Google "muốn" thu thập dữ liệu nhanh hơn, Tấn Phát Digital đề xuất các hành động:
Tăng cường liên kết nội bộ: Đặt liên kết tại trang chủ, chuyên mục chính hoặc bài viết có nhiều traffic.
Xây dựng Backlink chất lượng: Các liên kết từ trang uy tín trỏ về URL mục tiêu là bằng chứng thép cho độ quan trọng của trang.
Cập nhật nội dung thường xuyên: Duy trì lịch trình xuất bản ít nhất 3 lần mỗi tuần để tạo thói quen thu thập định kỳ cho bot.
Giai đoạn 4: Sử dụng các Giải pháp Lập chỉ mục Tức thì
Google Indexing API: Thông qua các công cụ như Rank Math, quản trị viên có thể gửi yêu cầu thu thập dữ liệu trực tiếp, giúp URL được index trong vòng vài giờ.
Giao thức IndexNow: Thông báo cho các công cụ tìm kiếm (Bing, Yandex) ngay khi có nội dung mới, giúp giảm tải cho máy chủ.
Phân tích Chuyên sâu về Báo cáo Thống kê Thu thập dữ liệu (Crawl Stats)
Để giải quyết triệt để lỗi "Discovered – currently not indexed", nhà quản trị cần theo dõi các mã phản hồi HTTP sau:
200 (OK): Trạng thái lý tưởng, cần đảm bảo cho các trang quan trọng nhất.
301 (Moved Permanently): Chuyển hướng vĩnh viễn, cần cập nhật liên kết trỏ trực tiếp đến đích cuối để tránh lãng phí ngân sách.
404 (Not Found): Trang không tồn tại, cần xóa khỏi sitemap nếu xuất hiện quá nhiều.
5xx (Server Error): Lỗi hệ thống nghiêm trọng, cần liên hệ nhà cung cấp hosting ngay lập tức.
429 (Too Many Requests): Tốc độ yêu cầu quá cao, cần giảm số lượng tài nguyên nhúng trên mỗi trang.
Ảnh hưởng của DNS và Cấu hình Mạng
Lỗi DNS_PROBE_FINISHED_NXDOMAIN là một rào cản lập chỉ mục chết người. Các nguyên nhân phổ biến bao gồm tên miền hết hạn, cấu hình DNS sai lệch hoặc bộ nhớ đệm DNS bị lỗi. Ngoài ra, Tấn Phát Digital cũng lưu ý bạn nên kiểm tra tường lửa hoặc các plugin bảo mật để đảm bảo không chặn IP chính thức của Googlebot.
Chiến lược Quản trị Nội dung và Thẩm quyền Chủ đề (Topical Authority)
Xây dựng các cụm nội dung (Content Clusters): Tổ chức nội dung theo cụm chủ đề liên quan giúp Google nhận diện trang web là một chuyên gia trong lĩnh vực.
Loại bỏ nội dung rác: Thực hiện kiểm toán nội dung để xóa bỏ các trang kém chất lượng, giúp Googlebot tập trung tài nguyên cho các trang thực sự giá trị.
Tầm quan trọng của Trải nghiệm Người dùng và Core Web Vitals
Google sử dụng dữ liệu lịch sử về trải nghiệm người dùng để dự đoán hiệu suất của trang mới. Việc cải thiện chỉ số LCP và CLS không chỉ giúp tăng thứ hạng mà còn là cách để "mở khóa" quy trình lập chỉ mục cho các trang đang bị kẹt. Đối với các trang sử dụng nhiều JavaScript, Tấn Phát Digital khuyến nghị triển khai Server-Side Rendering (SSR) để hỗ trợ quá trình render nhanh chóng của Googlebot.
Case Study Điển hình về Xử lý Lỗi Indexing
Tối ưu hóa liên kết nội bộ (JetOctopus): Một nghiên cứu thực tế cho thấy việc cải thiện cấu trúc liên kết nội bộ đã giúp tăng tỷ lệ thu thập dữ liệu của Googlebot thêm 30%, từ đó giải phóng hàng loạt URL đang bị kẹt ở trạng thái "Discovered".
Chuyển đổi từ Subdomain sang Subdirectory (Flick): Bằng cách di chuyển nội dung từ tên miền phụ sang thư mục con, website Flick đã đạt 9,6 triệu lượt truy cập hàng năm chỉ trong 12 tháng, nhờ việc tập trung thẩm quyền và ngân sách thu thập về một đầu mối duy nhất.
Tối ưu hóa nội dung cho AI Citations (MentorCruise): MentorCruise đã tái cấu trúc nội dung để AI dễ trích dẫn, thu hút hơn 11.500 lượt truy cập từ các công cụ tìm kiếm AI chỉ sau vài tháng triển khai chiến lược "AI-First SEO".
Giảm lãng phí ngân sách thu thập (E-commerce): Một trang thương mại điện tử đã giảm 73% lượng thu thập lãng phí bằng cách chặn các URL tham số (filters) không cần thiết, giúp Googlebot tập trung vào các trang sản phẩm chính.
Tái cấu trúc kiến trúc website (Atlassian): Việc xây dựng lại toàn bộ cấu trúc phân cấp trang web đã giúp Atlassian tăng 150% lượt nhấp chuột tự nhiên và 40% tỷ lệ chuyển đổi.
Cải thiện hạ tầng phục vụ (Auto Marketplace): Bằng cách nâng cấp server và tối ưu hóa thời gian phản hồi, một sàn giao dịch ô tô trực tuyến đã tăng gấp 19 lần tốc độ thu thập dữ liệu của Google và nhân đôi lưu lượng truy cập.
Khôi phục khả năng thu thập blog (Space Industry): Một blog chuyên ngành đã thu về hơn 160.000 lượt nhấp chỉ từ 18 bài viết sau khi giải quyết triệt để các rào cản khiến bài viết bị treo ở trạng thái "Discovered".
Giảm độ sâu nhấp chuột (Outdoor Equipment): Bằng cách làm phẳng cấu trúc URL (không quá 3 click từ trang chủ), một website bán đồ dã ngoại đã tăng 92% traffic và 104% doanh thu.
Cá nhân hóa Metadata (Hive Digital): Thay đổi công thức tiêu đề từ chung chung sang hướng mục đích người dùng ({Keyword} | {Benefit} | {Brand}) đã giúp loại bỏ hiện tượng "trùng lặp chủ đề" và thúc đẩy Google lập chỉ mục nhanh chóng.
Xử lý lỗi chặn Robots.txt (Audit thực tế): Một website vô tình chặn các trang quan trọng qua Robots.txt; sau khi gỡ bỏ, số lượng trang được thu thập đã tăng vọt 227% chỉ trong lần quét tiếp theo.
Câu Hỏi Thường Gặp (FAQ)
Lỗi này có tự biến mất không? Có, với các website nhỏ (< 10.000 trang) và nội dung chất lượng cao, Google sẽ tự động quay lại thu thập dữ liệu sau khi hệ thống ổn định.
Tại sao trạng thái "Ngày thu thập gần nhất" lại trống? Vì ở trạng thái "Discovered", Googlebot mới chỉ biết URL qua sitemap/link chứ chưa thực sự truy cập trang.
Sitemap có giúp sửa lỗi này triệt để không? Sitemap giúp Google "khám phá" nhanh hơn, nhưng không giải quyết được vấn đề "trì hoãn thu thập" nếu máy chủ của bạn đang quá tải.
Tôi có nên yêu cầu lập chỉ mục (Request Indexing) nhiều lần cho một URL không? Không nên. Yêu cầu nhiều lần không làm tăng tốc độ, Google sẽ tự xếp trang vào hàng đợi ưu tiên sau lần gửi đầu tiên.
Tại sao trang chủ được index nhưng các trang con lại bị lỗi "Discovered"? Thường do cấu trúc liên kết nội bộ yếu, khiến Google coi các trang con là không quan trọng hoặc do ngân sách thu thập bị cạn kiệt.
Nội dung tạo bằng AI có dễ bị dính lỗi này không? Có. Google có xu hướng dự đoán chất lượng và de-prioritize (giảm ưu tiên) thu thập đối với các trang nghi ngờ là nội dung AI chất lượng thấp hoặc trùng lặp.
Lỗi DNS_PROBE_FINISHED_NXDOMAIN ảnh hưởng thế nào đến Indexing? Nó khiến Googlebot không thể tìm thấy địa chỉ IP máy chủ, làm gián đoạn hoàn toàn quá trình thu thập dữ liệu.
Trong năm 2026, AI Mode ảnh hưởng gì đến việc lập chỉ mục? Dữ liệu AI Mode đã được tích hợp vào GSC, đòi hỏi nội dung phải có cấu trúc cực kỳ rõ ràng để được trích dẫn trong các câu trả lời của AI.
Giới hạn dung lượng trang mà Googlebot thu thập là bao nhiêu? Googlebot chỉ đọc 2MB đầu tiên của tệp HTML không nén; nếu trang quá nặng, nội dung phía dưới sẽ bị bỏ qua.
IndexNow là gì và nó có giúp ích gì không? Đây là giao thức thông báo tức thì cho Bing/Yandex về nội dung mới, giúp giảm tải cho server và tăng tốc độ hiện diện.
Làm sao để biết server đang quá tải bot? Bạn hãy kiểm tra báo cáo "Crawl Stats" trong GSC, nếu đường kẻ đỏ "Host Availability" bị vượt ngưỡng, nghĩa là server đang gặp khó khăn.
Tôi có nên chặn bot bằng robots.txt để tiết kiệm ngân sách không? Có, hãy chặn các trang không có giá trị SEO (như trang tìm kiếm, bộ lọc) để tập trung tài nguyên cho các trang mục tiêu.
Tại sao trang báo "Crawled – currently not indexed" dù nội dung tôi tự viết? Đây là vấn đề về chất lượng hoặc sự phù hợp với ý định tìm kiếm (Search Intent), nghiêm trọng hơn lỗi "Discovered".
Core Web Vitals có thực sự giúp index nhanh hơn? Có, website nhanh giúp Googlebot hoàn thành việc thu thập dữ liệu nhanh hơn, từ đó tăng hiệu suất lập chỉ mục trên cùng một mức ngân sách.
Tôi có thể yêu cầu Google giảm tốc độ thu thập dữ liệu không? Có, bạn có thể điều chỉnh "Crawl rate" trong cài đặt GSC nếu phát hiện Googlebot đang làm chậm website đáng kể.
Lỗi "Discovered – currently not indexed" là một tín hiệu về sự kém hiệu quả trong vận hành trang web. Tấn Phát Digital tin rằng việc quản trị tốt trạng thái này không chỉ giúp trang web xuất hiện nhanh hơn mà còn minh chứng cho một hệ thống kỹ thuật vững chắc. Quá trình lập chỉ mục là một cuộc đối thoại liên tục giữa máy chủ và thuật toán Google; hãy đảm bảo website của bạn luôn truyền tải những giá trị tích cực nhất.





![Hình ảnh đại diện của bài viết: [Series] Hỏi Chuyên Gia SEO — Kỳ 3: SEO Content hay AI Content — cái nào hiệu quả 2026](/_next/image?url=https%3A%2F%2Fcdn.tanphatdigital.com%2Fimages%2Fseries-hoi-chuyen-gia-seo-ky-3-seo-content-hay-ai-content-cai-nao-hieu-qua-2026.webp&w=1920&q=75)
![Hình ảnh đại diện của bài viết: [Series] Hỏi Chuyên Gia SEO — Kỳ 2: Chiến Lược Backlink Trong Kỷ Nguyên AI](/_next/image?url=https%3A%2F%2Fcdn.tanphatdigital.com%2Fimages%2Fseries-hoi-chuyen-gia-seo-ky-2-chien-luoc-backlink-trong-ky-nguyen-ai.webp&w=1920&q=75)