Trong bối cảnh tối ưu hóa công cụ tìm kiếm hiện đại, hiện tượng biểu đồ hiệu suất trên Google Search Console (GSC) đi ngang hoặc sụt giảm dù nội dung và liên kết ngược (backlink) vẫn được duy trì ở chất lượng cao đã trở thành một thách thức mang tính hệ thống. Tại Tấn Phát Digital, chúng tôi nhận thấy sự bế tắc này thường không xuất phát từ các yếu tố bên ngoài mà bắt nguồn từ những "điểm mù" kỹ thuật sâu xa bên trong kiến trúc trang web—những yếu tố mà thuật toán Google năm 2025 đã bắt đầu ưu tiên xử lý một cách nghiêm ngặt hơn bao giờ hết. Khi các phương pháp truyền thống như bơm nội dung hay xây dựng liên kết không còn mang lại kết quả, việc thấu hiểu các cơ chế phức tạp như Ngân sách thu thập dữ liệu (Crawl Budget), Tự xâu xé kỹ thuật (Technical Cannibalization) và Quy trình hiển thị (Rendering) là chìa khóa duy nhất để phá vỡ sự trì trệ.
Sự chuyển dịch dữ liệu lịch sử: Biến động tháng 9 năm 2025 và sự kết thúc của kỷ nguyên "lượt hiển thị ảo"
Để hiểu rõ tại sao biểu đồ GSC lại có những diễn biến bất thường, cần phải xem xét một thay đổi kỹ thuật quan trọng mà Google đã thực hiện vào giữa tháng 9 năm 2025. Đây không phải là một đợt cập nhật thuật toán lõi (Core Update) thông thường nhắm vào chất lượng nội dung, mà là một sự điều chỉnh nền tảng trong cách thức dữ liệu tìm kiếm được thu thập và báo cáo.
Sự loại bỏ tham số &num=100 và hệ quả đối với báo cáo hiệu suất
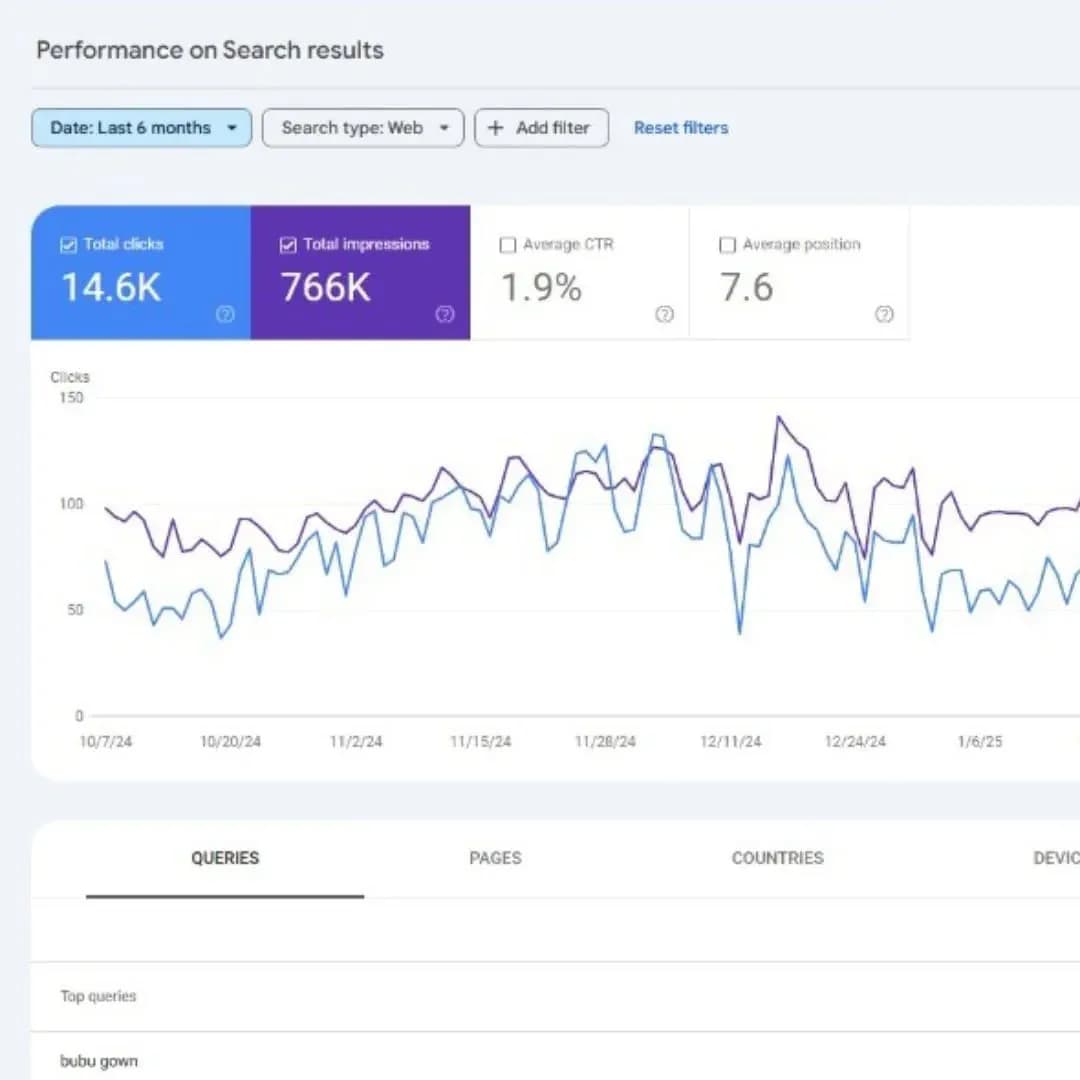
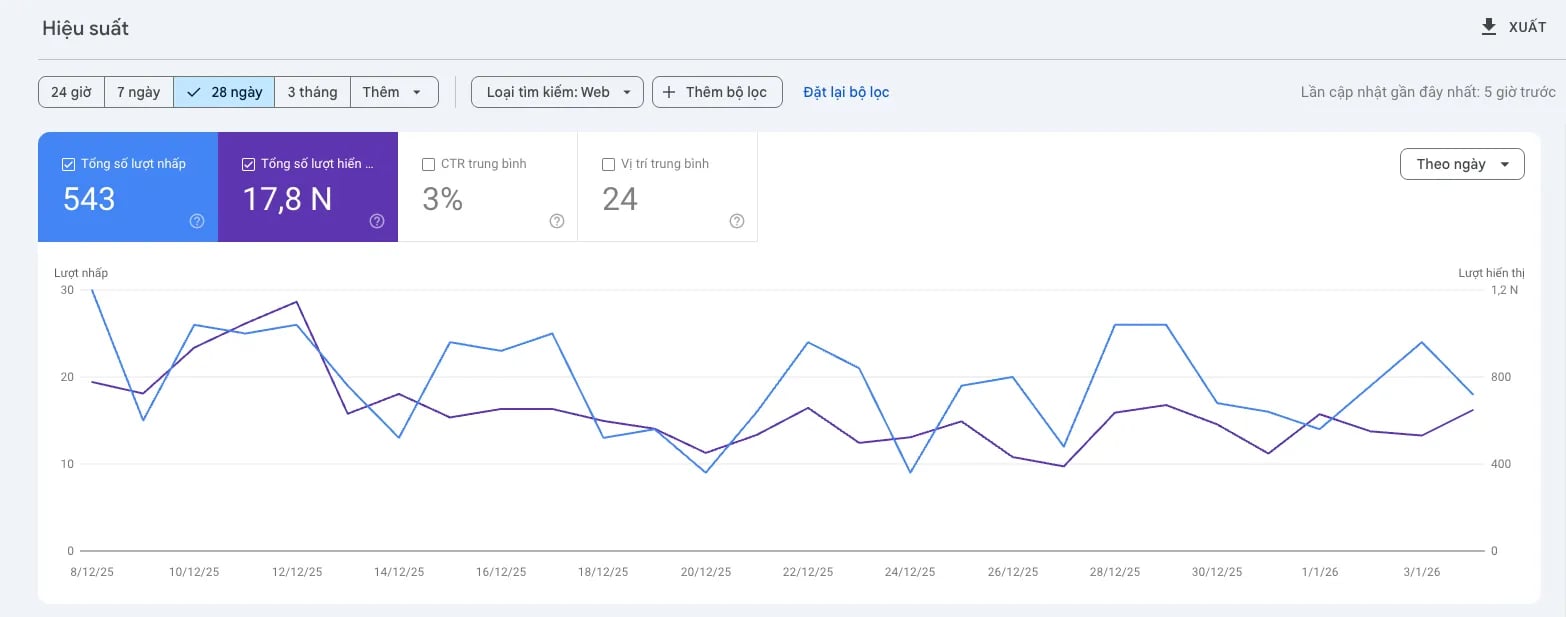
Từ ngày 12 đến 14 tháng 9 năm 2025, Google đã lặng lẽ vô hiệu hóa tham số &num=100 trong các URL tìm kiếm. Việc loại bỏ tính năng này đã gây ra một cú sốc dữ liệu trên diện rộng, với khoảng 87,7% các trang web ghi nhận sự sụt giảm đáng kể về lượt hiển thị (Impressions) trên GSC.
Thực tế, một phần lớn lượt hiển thị trước đây không đến từ người dùng thực mà đến từ các bot và công cụ cào dữ liệu. Theo phân tích từ Tấn Phát Digital, dưới đây là sự thay đổi trong cấu trúc dữ liệu sau cột mốc này:
Lượt hiển thị (Impressions): Ghi nhận mức giảm từ 30% - 50%. Nguyên nhân do Google loại bỏ lượt hiển thị từ bot và scraper vốn thường xuyên sử dụng tham số
&num=100để quét kết quả.Lượt nhấp (Clicks): Duy trì trạng thái ổn định hoặc biến động nhẹ. Điều này chứng minh người dùng thực vẫn nhấp chuột vào các vị trí Top 10 như cũ, không bị ảnh hưởng bởi thay đổi kỹ thuật trên.
Vị trí trung bình (Average Position): Có xu hướng cải thiện rõ rệt (ví dụ: từ 25 lên 15). Đây thực tế là một "ảo ảnh toán học" do việc loại bỏ các từ khóa xếp hạng thấp (vốn bị bot tạo ấn tượng) khỏi mẫu số tính trung bình.
Tỷ lệ nhấp (CTR): Tăng đáng kể do số lượt nhấp giữ nguyên trong khi mẫu số (lượt hiển thị) đã bị sụt giảm mạnh sau quá trình làm sạch dữ liệu.
Sự cải thiện về vị trí trung bình trong giai đoạn này thường không phải là sự thăng tiến thực sự về thứ hạng. Nếu một quản trị viên thấy vị trí trung bình nhảy vọt nhưng lưu lượng truy cập không tăng, đó đơn giản là quá trình "làm sạch" dữ liệu để phản ánh chính xác hành vi của con người thay vì bot.
Sự trỗi dậy của AI Overviews và hiện tượng "Zero-Click"
Thuật toán Google năm 2025 cũng đánh dấu sự trưởng thành của AI Overviews (AIO). AI Overviews trích xuất nội dung từ các trang web để cung cấp câu trả lời trực tiếp. Điều này tạo ra một nghịch lý mà Tấn Phát Digital thường xuyên cảnh báo khách hàng: một trang web có thể được Google tin tưởng trích dẫn nội dung (tăng lượt hiển thị), nhưng số lượt nhấp thực tế lại giảm mạnh vì người dùng đã có được thông tin cần thiết mà không cần truy cập vào website.
Theo các nghiên cứu, tỷ lệ tìm kiếm không nhấp chuột (zero-click) đã chạm mức gần 60% tại các thị trường phát triển. Đây là một nguyên nhân quan trọng khiến biểu đồ GSC đi ngang: trang web vẫn giữ vững vị trí nhưng hành vi của người dùng đã bị thay đổi bởi cấu trúc SERP mới.
Ngân sách thu thập dữ liệu (Crawl Budget): Đặc quyền thay vì quyền lợi mặc định
Trong kỷ nguyên của AI, Googlebot không còn thu thập dữ liệu một cách vô hạn. Năm 2025, Google đã chính thức chuyển dịch sang mô hình "thu thập dữ liệu có chọn lọc", nơi ngân sách thu thập dữ liệu trở thành một loại tài nguyên quý giá mà các website phải "kiếm" được thông qua hiệu suất kỹ thuật.
Cơ chế "Quality Pre-check" (Kiểm tra chất lượng sơ bộ) năm 2026
Google hiện thực hiện một đánh giá nhanh dựa trên các tín hiệu kỹ thuật bề mặt trước khi quyết định thu thập toàn bộ nội dung. Các yếu tố trọng yếu trong quy trình này bao gồm:
Tốc độ phản hồi máy chủ (TTFB): Đây là yếu tố có trọng số rất cao. Nếu máy chủ phản hồi chậm (trên 200ms), Googlebot sẽ chủ động giảm tần suất quét để tránh gây quá tải cho hệ thống.
Tính độc nhất của nội dung (Content Uniqueness): Trọng số rất cao. Các nội dung trùng lặp hoặc được tạo hàng loạt bằng AI không có giá trị gia tăng sẽ bị Googlebot dừng thu thập ngay lập tức.
Core Web Vitals (Đặc biệt là LCP): Trọng số cao. Các trang có chỉ số LCP vượt quá 2.5 giây bị coi là trải nghiệm kém và bị hạ mức ưu tiên trong hàng đợi thu thập dữ liệu.
Bảo mật HTTPS: Trọng số trung bình. Các trang web không bảo mật hoặc gặp lỗi chứng chỉ SSL sẽ bị hạn chế thu thập để đảm bảo an toàn cho người dùng tìm kiếm.
Việc biểu đồ GSC đi ngang thường là hệ quả của việc Googlebot ngừng khám phá các trang mới hoặc không cập nhật các thay đổi trên các trang cũ do ngân sách thu thập bị cạn kiệt.
Sự quản lý hiệu quả tài nguyên thu thập dữ liệu
Ngân sách thu thập dữ liệu bị lãng phí là một "điểm mù" kỹ thuật mà nhiều quản trị viên bỏ qua. Tấn Phát Digital khuyến nghị bạn cần rà soát ngay các yếu tố gây lãng phí sau:
Chuỗi chuyển hướng (Redirect Chains): Mỗi bước nhảy chuyển hướng khiến Googlebot tốn thêm tài nguyên. Google khuyến nghị không nên vượt quá 2 bước nhảy trong một yêu cầu thu thập.
Lỗi Soft 404: Những trang không tồn tại nhưng trả về mã trạng thái 200 (OK) buộc Googlebot phải xử lý nội dung vô ích, gây lãng phí nghiêm trọng.
Tham số URL vô hạn: Các hệ thống lọc sản phẩm không được kiểm soát có thể tạo ra hàng triệu URL với nội dung tương đồng, tạo thành các "bẫy thu thập dữ liệu" (crawl traps).
Tự xâu xé kỹ thuật (Technical Cannibalization): Khi cấu trúc hệ thống tự hủy hoại thứ hạng
Tự xâu xé kỹ thuật xảy ra khi các thành phần của hệ thống—như URL tham số, trang lọc, hoặc cấu trúc chuyển hướng—làm phân tán các tín hiệu xếp hạng và thẩm quyền của trang chính.
Cơ chế phân mảnh thẩm quyền tìm kiếm (Search Equity Fragmentation)
Năm 2025, khái niệm "Search Equity" (Tài sản tìm kiếm) trở thành tâm điểm đánh giá sức mạnh domain. Công thức tính toán sự mất mát giá trị do xâu xé kỹ thuật được mô tả như sau:
Search Equity Gap = Lost Qualified Traffic + Lost Discoverability + Lost Intent Coverage
Khi một trang web có nhiều phiên bản cho cùng một nội dung, Googlebot sẽ phải chia sẻ sức mạnh xếp hạng giữa các URL này. Thay vì có một trang duy nhất đạt vị trí Top 1, bạn sẽ có nhiều trang cùng nằm ở vị trí Top 20, khiến traffic tổng thể bị đình trệ.
Các dạng xâu xé kỹ thuật phổ biến và giải pháp từ Tấn Phát Digital
Faceted Navigation (Điều hướng bộ lọc): Các tổ hợp bộ lọc tạo ra hàng ngàn URL tương tự. Giải pháp: Sử dụng thẻ Canonical tuyệt đối và chặn các tổ hợp lọc không cần thiết trong file robots.txt.
Bất đối xứng Mobile/Desktop: Sự khác biệt trong cấu trúc HTML hoặc liên kết nội bộ giữa hai phiên bản thiết bị. Giải pháp: Đảm bảo tính nhất quán tuyệt đối của nội dung và dữ liệu cấu trúc trên mọi thiết bị (Responsive Design).
Lỗi đa ngôn ngữ (Internationalization): Cấu hình thẻ Hreflang sai khiến các phiên bản ngôn ngữ cạnh tranh lẫn nhau. Giải pháp: Kiểm tra tính đối xứng của thẻ Hreflang và đảm bảo các thẻ chỉ trỏ về đúng phiên bản quốc gia.
Vòng lặp Canonical (Canonical Loops): Thẻ canonical trỏ vòng quanh hoặc trỏ về trang lỗi. Giải pháp: Kiểm toán định kỳ để đảm bảo thẻ canonical luôn trỏ về URL gốc có mã trạng thái 200.
Rendering và "Điểm mù" nội dung vô hình
"Điểm mù" lớn nhất hiện nay nằm ở sự khác biệt giữa nội dung bạn thấy trong trình duyệt và nội dung mà Googlebot thực sự lập chỉ mục được, đặc biệt là với các website nặng về JavaScript.
Sự trì trệ trong hàng đợi hiển thị (The Rendering Queue)
Dù Googlebot đã có khả năng xử lý JavaScript, quá trình này vẫn đòi hỏi nhiều tài nguyên. Googlebot thường thực hiện qua hai giai đoạn: Thu thập mã nguồn HTML ban đầu và sau đó mới đưa vào hàng đợi hiển thị để thực thi JavaScript. Sự chậm trễ trong hàng đợi này có thể kéo dài hàng tuần, khiến nội dung mới không thể xuất hiện trên SERP kịp thời.
Server-Side Rendering (SSR) vs. Client-Side Rendering (CSR)
Dựa trên kinh nghiệm triển khai của Tấn Phát Digital, chúng tôi phân loại các phương pháp hiển thị như sau:
Server-Side Rendering (SSR): Nội dung hiển thị ngay lập tức cho bot, lập chỉ mục nhanh nhất và hỗ trợ cực tốt cho AI Overviews. Tuy nhiên, nó gây tải nặng hơn cho máy chủ. Đây là lựa chọn ưu tiên cho trang nội dung, tin tức và E-commerce.
Client-Side Rendering (CSR): Mang lại trải nghiệm người dùng mượt mà và giảm tải cho máy chủ nhưng tiềm ẩn nguy cơ nội dung không được lập chỉ mục kịp thời. Phương pháp này chỉ nên dùng cho các ứng dụng web mang tính công cụ, yêu cầu tương tác cao.
Hybrid (Hydration): Kết hợp sự nhanh chóng của SSR và tính tương tác của CSR. Mặc dù kỹ thuật triển khai phức tạp, đây được coi là "tiêu chuẩn vàng" cho các nền tảng web hiện đại năm 2025.
Quy trình kiểm tra và khắc phục từ Tấn Phát Digital
Khi đối mặt với một biểu đồ đi ngang, bạn cần thực hiện một cuộc điều tra có hệ thống:
Phân tích phân vùng bằng Biểu đồ Bong bóng (Bubble Chart): Sử dụng Looker Studio để phân loại từ khóa. Chú ý đặc biệt đến các từ khóa ở phân vùng có CTR cao nhưng vị trí thấp—đây là "mỏ vàng" bị bỏ quên do các lỗi kỹ thuật ngăn cản sự thăng hạng.
Kiểm soát báo cáo "Indexing": Rà soát các trạng thái như "Đã thu thập dữ liệu - hiện chưa được lập chỉ mục" hoặc "Trùng lặp, Google chọn canonical khác với người dùng" để phát hiện ngay các lỗi tự xâu xé.
Tối ưu hóa tốc độ phản hồi: Đảm bảo TTFB dưới 200ms. Sử dụng CDN và nén hình ảnh định dạng WebP/AVIF để giải phóng tiềm năng tăng trưởng của biểu đồ GSC.
Case Studies: Thực tế phục hồi traffic từ các "điểm mù" kỹ thuật
Dưới đây là các ví dụ thực tế về việc áp dụng Technical SEO để phá vỡ sự trì trệ của biểu đồ GSC mà Tấn Phát Digital đã tổng hợp:
Case Study 1: Visit Seattle – Cắt tỉa nội dung để hồi sinh thứ hạng (2025): Website của một tổ chức du lịch gặp tình trạng "phình to" (site bloat) với hơn 8.400 trang nhưng traffic đi ngang. Bằng cách thực hiện audit và pruning (loại bỏ) 70% số trang kém chất lượng (giảm xuống còn 2.535 trang), điểm sức khỏe website đã tăng 850%, giúp các trang chính còn lại bứt phá thứ hạng mạnh mẽ.
Case Study 2: Phục hồi bài viết "Thermal Pollution in India" (2025): Một bài viết đang đứng Top 1 đột ngột rơi xuống vị trí #15 sau khi cài đặt quảng cáo gây ảnh hưởng trải nghiệm và thay đổi Meta Tags. Sau khi gỡ bỏ quảng cáo, khôi phục Meta Tags gốc và bổ sung thêm 2 case study nội dung, bài viết đã quay trở lại Top 1 chỉ trong 5 ngày.
Case Study 3: Phục hồi 200% traffic cho Thương hiệu Cao cấp (2025): Sau khi ra mắt website mới, một nhãn hàng cao cấp sụt giảm 50% traffic do lỗi chuyển hướng và cấu trúc sitemap. Bằng cách giải quyết triệt để các redirect chains và tối ưu hóa lại liên kết nội bộ, website đã đạt mức tăng trưởng 200% trong vòng 6 tháng mà không cần xây dựng thêm backlink.
Câu hỏi thường gặp (FAQ) về Google Search Console & Technical SEO 2026
Dưới đây là giải đáp cho các thắc mắc phổ biến nhất khi biểu đồ GSC của bạn đi ngang hoặc gặp lỗi:
Tại sao lượt hiển thị (Impressions) giảm mạnh trong khi vị trí trung bình lại tăng? Đây thường là hệ quả của đợt cập nhật tháng 9/2025 khi Google loại bỏ tham số &num=100. Các lượt hiển thị ảo từ bot và scraper bị xóa bỏ, khiến dữ liệu của bạn trở nên "sạch" hơn. Vị trí trung bình tăng lên là do các từ khóa xếp hạng thấp (ngoài Top 20) không còn lượt hiển thị để kéo giảm con số trung bình xuống.
Sự khác biệt giữa "Đã khám phá - hiện chưa được lập chỉ mục" và "Đã thu thập dữ liệu - hiện chưa được lập chỉ mục" là gì? "Đã khám phá" (Discovered) nghĩa là Google đã biết URL nhưng chưa đủ ngân sách hoặc ưu tiên để thu thập. "Đã thu thập dữ liệu" (Crawled) nghĩa là Google đã đọc nội dung nhưng quyết định không đưa vào chỉ mục, thường do chất lượng nội dung thấp hoặc lỗi rendering khiến Google thấy một trang rỗng.
Làm thế nào để tối ưu Ngân sách thu thập dữ liệu (Crawl Budget) cho website lớn? Bạn cần ưu tiên cải thiện tốc độ máy chủ (TTFB < 200ms), loại bỏ các chuỗi chuyển hướng quá 2 bước, chặn các URL tham số không cần thiết bằng robots.txt và sử dụng giao thức IndexNow để thông báo cập nhật nội dung tức thì cho công cụ tìm kiếm.
Google có phạt lỗi nội dung trùng lặp (Duplicate Content) không? Google thường không "phạt" theo nghĩa thủ công, nhưng nó sẽ "loại bỏ" các trang trùng lặp khỏi kết quả tìm kiếm để tránh gây loãng SERP. Điều này làm lãng phí Crawl Budget và phân tán sức mạnh xếp hạng của trang chính.
Làm sao để biết Google có đang gặp "điểm mù" khi hiển thị JavaScript của tôi không? Hãy sử dụng công cụ URL Inspection trong GSC, chọn "View crawled page" và kiểm tra tab HTML. Nếu các đoạn văn bản quan trọng hoặc link điều hướng không xuất hiện trong mã nguồn này, Google đang bị "mù" đối với nội dung của bạn.
Phá vỡ sự trì trệ bằng tư duy kỹ thuật hệ thống
Biểu đồ Google Search Console đi ngang không bao giờ là một hiện tượng ngẫu nhiên. Trong kỷ nguyên thuật toán năm 2025, đó là lời cảnh báo về sự mất kết nối giữa giá trị nội dung và khả năng tiếp cận kỹ thuật của công cụ tìm kiếm.
Tấn Phát Digital tin rằng chìa khóa không nằm ở việc làm nhiều hơn, mà là làm thông minh hơn: làm sạch dữ liệu khỏi các lượt hiển thị ảo, tập trung nguồn lực thu thập vào các trang có giá trị nhất, và đảm bảo rằng mọi câu chữ bạn viết đều được Googlebot "nhìn thấy" một cách trọn vẹn. Sự trì trệ hôm nay chính là cơ hội để tái cấu trúc website trở nên vững chắc hơn cho tương lai.