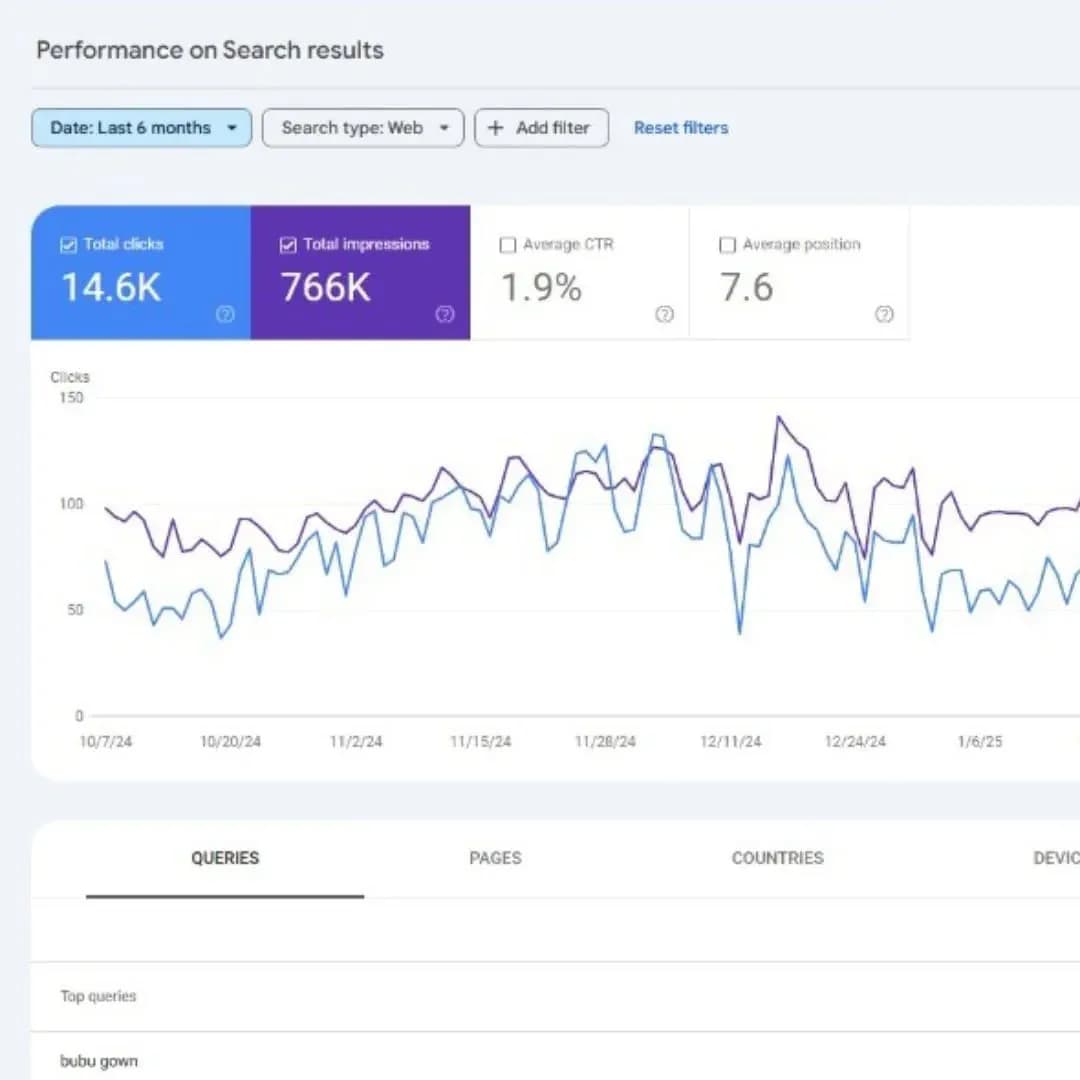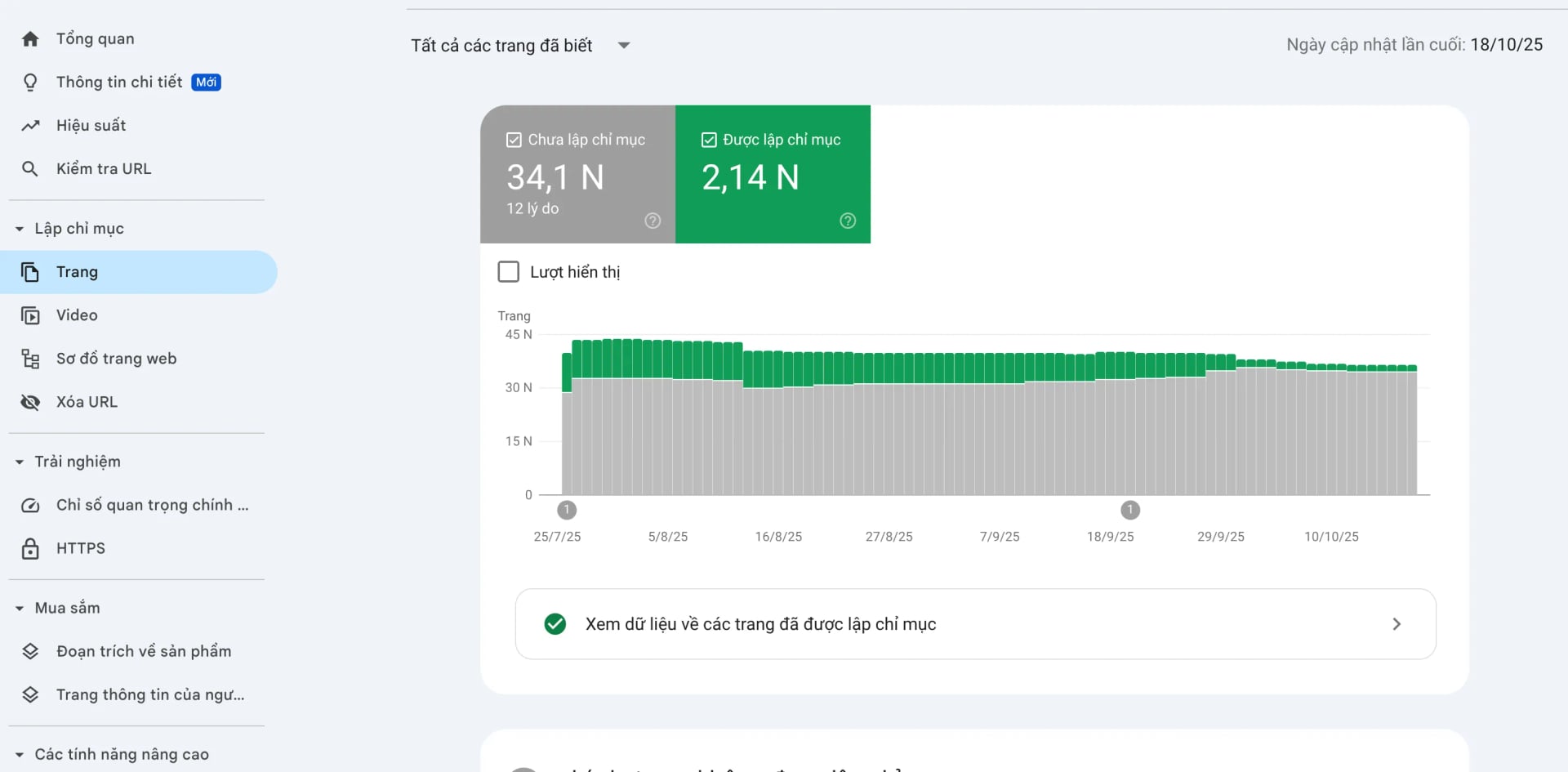
Trong bối cảnh hệ sinh thái kỹ thuật số ngày càng phức tạp, việc quản trị khả năng hiển thị của website trên công cụ tìm kiếm không còn đơn thuần là câu chuyện về từ khóa hay liên kết. Lập chỉ mục (indexing) đã trở thành một "đặc quyền" mà Google chỉ dành cho những nội dung đáp ứng được các tiêu chuẩn khắt khe về kỹ thuật và giá trị người dùng. Báo cáo lập chỉ mục trang (Page Indexing Report) trong Google Search Console (GSC) đóng vai trò như một bản đồ chẩn đoán, giúp các nhà quản trị website hiểu rõ cách Googlebot khám phá, thu thập dữ liệu và lưu trữ thông tin. Bài báo cáo này cung cấp một cái nhìn toàn diện, sâu sắc và thực chiến về việc xử lý các lỗi không index, đúc kết từ những biến động thuật toán mới nhất và kinh nghiệm thực chiến từ đội ngũ Tấn Phát Digital.
Hệ Thống Lập Chỉ Mục Của Google: Cơ Chế Vận Hành Và Những Rào Cản Hiện Đại
Để xử lý triệt để các lỗi không lập chỉ mục, trước tiên cần thấu hiểu quy trình ba giai đoạn của Google:
Khám phá (Discovery): Google tìm thấy URL của bạn thông qua sơ đồ trang web (sitemaps) hoặc các liên kết từ các trang đã biết. Tín hiệu thành công là URL xuất hiện trong báo cáo "Đã phát hiện".
Thu thập dữ liệu (Crawling): Googlebot truy cập và đọc mã nguồn trang. Tín hiệu thành công là mục "Lần thu thập dữ liệu gần nhất" có ngày tháng cụ thể.
Lập chỉ mục (Indexing): Google phân tích, hiểu nội dung và lưu vào cơ sở dữ liệu. Tín hiệu thành công là URL hiển thị trạng thái "Đã lập chỉ mục" màu xanh.
Trong những năm gần đây, Google đã chuyển dịch từ tư duy "chỉ mục hóa mọi thứ" sang "chỉ mục hóa những gì có giá trị". Sự bùng nổ của nội dung AI buộc Google phải thắt chặt ngân sách thu thập dữ liệu (crawl budget) và nâng cao ngưỡng chất lượng. Do đó, theo quan điểm của Tấn Phát Digital, các trạng thái lỗi trong GSC không chỉ là hỏng hóc kỹ thuật mà thường là những phán xét về giá trị của website đối với người dùng.
Danh Mục Phân Tích Chi Tiết 13 Nguyên Nhân Google Không Index
Dưới đây là bảng chẩn đoán 13 lý do chính khiến trang không được lập chỉ mục, kèm theo hướng xử lý chuyên sâu được đúc kết từ quy trình thực chiến của Tấn Phát Digital:
Discovered – Currently Not Indexed (Đã phát hiện thấy – hiện chưa được lập chỉ mục): Google đã biết URL nhưng chưa thu thập dữ liệu (Crawl).
Hướng xử lý: Tối ưu Crawl Budget bằng cách loại bỏ liên kết rác khỏi Sitemap; chặn trang không quan trọng qua Robots.txt; xây dựng liên kết nội bộ mạnh mẽ.
Crawled – Currently Not Indexed (Đã thu thập dữ liệu – hiện chưa được lập chỉ mục): Google đã thu thập dữ liệu nhưng quyết định không index.
Hướng xử lý: Cải thiện chất lượng nội dung, tránh nội dung mỏng hoặc trùng lặp; tối ưu Core Web Vitals và UX; xử lý lỗi ăn thịt từ khóa.
Excluded by Noindex Tag (Bị loại trừ bởi thẻ 'noindex'): URL có gắn thẻ
<meta name="robots" content="noindex">.Hướng xử lý: Gỡ bỏ thẻ noindex khỏi mã nguồn nếu đó là trang cần index; sau đó yêu cầu lập chỉ mục lại qua GSC.
Blocked by Robots.txt (Bị chặn bằng tệp robots.txt): URL bị chặn thu thập bởi lệnh Disallow trong robots.txt.
Hướng xử lý: Rà soát và xóa lệnh Disallow không mong muốn; lưu ý chặn robots chỉ ngăn crawl chứ không ngăn index 100%.
Duplicate, Google chose different canonical than user (Trang trùng lặp, Google đã chọn trang chính tắc khác): Google chọn URL khác tốt hơn để index vì nội dung quá giống nhau hoặc thẻ Canonical bị thiết lập sai.
Hướng xử lý: Đồng nhất dạng URL (có/không dấu gạch chéo cuối); đảm bảo nội dung các URL thực sự khác biệt.
Duplicate Without User-Selected Canonical (Trang trùng lặp, người dùng chưa chọn trang chính tắc): URL bị đánh giá trùng lặp nhưng chưa có thẻ Canonical (thường là trang phân trang hoặc feed).
Hướng xử lý: Gắn thẻ Canonical trỏ về trang gốc; chặn index các trang không cần thiết (như /feed/) để tiết kiệm Crawl Budget.
Alternate page with proper canonical tag (Trang thay thế có thẻ chính tắc thích hợp): URL này đang trỏ Canonical sang URL khác đã được index.
Hướng xử lý: Nếu đúng mục đích (trang thay thế), không cần làm gì; nếu là lỗi, điều chỉnh thẻ Canonical trỏ về chính nó.
Page with Redirect (Trang có lệnh chuyển hướng): URL đang chuyển hướng (301/302) đến URL khác.
Hướng xử lý: Đảm bảo URL đích là URL hợp lệ và đã được index.
Redirect error (Lỗi chuyển hướng): Chuỗi chuyển hướng quá dài, vòng lặp, hoặc URL không hợp lệ.
Hướng xử lý: Phá bỏ vòng lặp; rút ngắn chuỗi chuyển hướng (dưới 3 bước); đảm bảo đích đến trả về mã 200 OK.
Server error (5xx) (Lỗi máy chủ): Máy chủ không ổn định hoặc quá tải.
Hướng xử lý: Liên hệ nhà cung cấp hosting để nâng cấp hiệu suất; đảm bảo URL trả về mã 200 OK ổn định.
Not Found (404) (Không tìm thấy): URL không tồn tại.
Hướng xử lý: Nếu URL quan trọng, hãy khôi phục hoặc redirect 301 về trang liên quan; tạo trang 404 thân thiện để tối ưu UX.
Soft 404 (404 mềm): URL không có nội dung chính nhưng server vẫn báo mã 200 OK.
Hướng xử lý: Bổ sung nội dung chính cho trang; nếu không dùng nữa hãy đảm bảo nó trả về mã 404/410 chính xác.
Indexed, though blocked by robots.txt (Đã lập chỉ mục mặc dù bị chặn bởi robots.txt): Trang nằm trong nhóm Xanh nhưng bị chặn thu thập dữ liệu.
Hướng xử lý: Nếu cần chặn hẳn, gỡ Disallow trong robots.txt -> thêm thẻ noindex -> đợi Google gỡ bỏ -> sau đó mới thêm lại lệnh Disallow.
JavaScript SEO - Mô Hình Lập Chỉ Mục Hai Đợt (Two-Wave Indexing)
Tấn Phát Digital nhấn mạnh rằng Google không xử lý JavaScript ngay lập tức. Quá trình này diễn ra theo hai đợt:
Đợt 1 (Raw HTML): Googlebot quét mã nguồn tĩnh từ server. Nếu thẻ canonical hoặc meta tag được tiêm bằng JS, Google có thể bỏ qua ở giai đoạn này.
Đợt 2 (Rendered DOM): Googlebot đưa trang vào hàng đợi kết xuất (Rendering Queue) để thực thi JS. Quá trình này có thể trễ từ vài ngày đến vài tuần, tạo ra Latency Gap khiến nội dung mới không hiển thị ngay.
Giải pháp đề xuất: Sử dụng Server-Side Rendering (SSR) hoặc Hybrid Rendering (như Next.js, Nuxt.js) để gửi HTML hoàn chỉnh cho bot, giúp bỏ qua hàng đợi kết xuất và index tức thì.
Server Log Analysis – "Sự Thật Gốc" Cho SEO Enterprise
Đối với các website quy mô lớn (trên 10.000 trang), dữ liệu trong Search Console thường bị lọc và gộp (sampled data). Tấn Phát Digital sử dụng Server Log Analysis để có cái nhìn chính xác 100% về hành vi của bot:
Phát hiện Crawl Waste: Xác định các URL bị bot quét liên tục nhưng không có giá trị (như tham số theo dõi, trang tìm kiếm nội bộ) để chặn kịp thời.
Xác minh IP Googlebot: Đảm bảo không có các bot giả mạo đang hút băng thông hoặc gây nhiễu dữ liệu.
Đo lường Crawl Frequency: Theo dõi tần suất bot ghé thăm các trang "Authority" (trang trụ cột). Nếu bot hiếm khi quay lại, đó là dấu hiệu cấu trúc liên kết nội bộ đang yếu.
Phân Tích Trạng Thái "Đã Phát Hiện - Hiện Chưa Được Lập Chỉ Mục" (Discovered – Currently Not Indexed)
Trạng thái này (DCNI) có nghĩa là Google đã biết đến sự tồn tại của URL nhưng quyết định trì hoãn việc ghé thăm. Đây là vấn đề liên quan mật thiết đến sự ưu tiên và hiệu suất hệ thống.
Cơ Chế Trì Hoãn Và Ngân Sách Thu Thập Dữ Liệu
Googlebot không có nguồn lực vô hạn. Đối với mỗi website, Google phân bổ một "ngân sách thu thập dữ liệu" dựa trên độ tin cậy và hiệu suất máy chủ. Nếu website không thường xuyên cập nhật nội dung mới, thiếu liên kết nội bộ chất lượng hoặc có quá nhiều nội dung rác, Google sẽ giảm mức độ ưu tiên.
Chiến Lược Xử Lý Lỗi DCNI Từ Gốc Rễ
Tấn Phát Digital khuyến nghị các giải pháp sau để cải thiện tình trạng DCNI:
Tối ưu tốc độ phản hồi (TTFB): Máy chủ chậm khiến Googlebot e ngại gây sập web. Giải pháp là nâng cấp hosting, sử dụng CDN và tối ưu cache.
Cải thiện độ sâu URL: Trang nằm quá sâu (cách trang chủ hơn 3 lần nhấp) ít được ưu tiên. Hãy đưa các trang quan trọng lên menu hoặc sidebar.
Tăng tần suất cập nhật: Website ít thay đổi không kích thích bot ghé thăm. Hãy duy trì lịch đăng bài đều đặn và chất lượng.
Nâng cao chất lượng Sitemap: Sitemap chứa trang rác làm lãng phí ngân sách. Hãy loại bỏ các trang noindex hoặc lỗi 404 khỏi sitemap.
Giải Mã Trạng Thái "Đã Thu Thập Dữ Liệu - Hiện Chưa Được Lập Chỉ Mục" (Crawled – Currently Not Indexed)
Trạng thái này (CCNI) là một tín hiệu cảnh báo đỏ về chất lượng. Googlebot đã thực sự ghé thăm, đọc nội dung nhưng quyết định từ chối đưa vào chỉ mục vì đánh giá trang web không mang lại giá trị gia tăng hoặc quá mỏng (thin content).
Công Thức Đột Phá Chỉ Mục Cho Trang CCNI
Để đưa một trang thoát khỏi "vùng tối" CCNI, Tấn Phát Digital áp dụng các bước tối ưu chuyên sâu:
Áp dụng công thức tiêu đề hướng mục đích (Intent-Driven Title): Sử dụng cấu trúc
{Từ khóa chính} | {Lợi ích cụ thể} | {Tên thương hiệu}để khẳng định giá trị độc nhất.Nâng cấp nội dung theo tiêu chuẩn E-E-A-T: Bổ sung hình ảnh tự chụp, video hướng dẫn, bảng dữ liệu thực tế và trích dẫn chuyên gia để tăng tính độc bản.
Xử lý trùng lặp chủ đề: Nếu có nhiều trang cùng nhắm đến một từ khóa, hãy sử dụng lệnh 301 redirect để hợp nhất hoặc dùng thẻ canonical trỏ về trang mạnh nhất.
Kiểm tra lỗi kết xuất (Rendering): Đảm bảo Googlebot không nhìn thấy một trang trắng do lỗi JavaScript bằng cách sử dụng công cụ "Kiểm tra URL trực tiếp".
Khắc Phục Lỗi Kỹ Thuật: Từ Chỉ Thị Ngăn Chặn Đến Chuyển Hướng
Các lỗi kỹ thuật thường là nguyên nhân khiến website "biến mất" đột ngột. Tấn Phát Digital rà soát các yếu tố sau:
Thẻ Meta Noindex: Kiểm tra trong thẻ
<head>xem có mã<meta name="robots" content="noindex">hay không và xóa bỏ nếu cần.Tệp Robots.txt: Đảm bảo không sử dụng lệnh
Disallowcho các thư mục nội dung quan trọng.Cài đặt WordPress: Vào phần Cài đặt > Đọc và đảm bảo ô "Ngăn chặn công cụ tìm kiếm" không bị tích.
Tệp.htaccess: Rà soát các quy tắc
X-Robots-Tagtrong cấu hình server có thể đang chặn bot ngầm.
Đối với lỗi chuyển hướng (Redirect Error), cần tránh các "vòng lặp" (A trỏ về B, B trỏ về A) và các "chuỗi dài" (quá 3 bước trung gian). Googlebot sẽ bỏ cuộc nếu chuỗi chuyển hướng quá phức tạp.
Quy Trình Xác Nhận Lỗi (Validate Fix) Thủ Công
Sau khi đã thực hiện các thay đổi kỹ thuật, nhà quản trị cần thực hiện quy trình xác nhận chính thức trên GSC:
Trạng thái "Chưa bắt đầu": Lỗi mới được phát hiện. Hành động: Sửa lỗi xong mới nhấn Validate Fix.
Trạng thái "Khởi đầu tốt": Các mẫu URL đầu tiên đã vượt qua kiểm tra của Google. Hành động: Tiếp tục chờ đợi.
Trạng thái "Đạt" (Passed): Lỗi đã được khắc phục hoàn toàn. Hành động: Theo dõi traffic và thứ hạng.
Trạng thái "Không đạt" (Failed): Vẫn còn ít nhất 1 URL bị lỗi. Hành động: Kiểm tra URL gây lỗi cụ thể và thực hiện lại.
Xem thêm: Dịch vụ thiết kế website uy tín tại Hồ Chí Minh
Tối Ưu Hóa Nâng Cao Với Google Indexing API
Với các website tin tức hoặc thương mại điện tử cần tốc độ, Tấn Phát Digital ưu tiên sử dụng Google Indexing API. Phương pháp này cho phép đẩy URL trực tiếp vào giai đoạn Crawling, giúp bài viết được index chỉ sau vài phút đến vài giờ thay vì vài tuần. Việc tích hợp thông qua các công cụ như Rank Math (Instant Indexing) kết hợp với tệp khóa JSON từ Google Cloud là giải pháp tối ưu nhất hiện nay.
So Sánh Các Công Cụ Hỗ Trợ Lập Chỉ Mục Năm 2026
Việc lựa chọn công cụ hỗ trợ đóng vai trò then chốt trong hiệu quả SEO Technical:
Rank Math (Bản miễn phí): Hỗ trợ Instant Indexing (API), trình quản lý chuyển hướng (Redirect), Schema nâng cao và giám sát lỗi 404. Đây là lựa chọn hàng đầu cho các SEOer chuyên nghiệp.
Yoast SEO (Bản miễn phí): Tập trung vào tính ổn định và dễ dùng cho người mới, nhưng các tính năng như Redirect Manager thường yêu cầu bản trả phí (Premium).
Tầm Nhìn Chiến Lược Từ Tấn Phát Digital
1. Source Term Vector: Kết Quả Toán Học Của Topical Authority
Trong năm 2026, thẩm quyền chủ đề (Topical Authority) không còn là một khái niệm mơ hồ. Nó được cụ thể hóa thành "Source Term Vector" – một hồ sơ chuyên môn khái niệm mô tả các chủ đề mà website được liên kết chặt chẽ nhất trong hệ thống của Google.
Cơ chế hình thành: Source Term Vector không được tạo ra từ một bài viết đơn lẻ mà được định hình từ dữ liệu tích lũy theo thời gian.
Vai trò: Đây là kết quả toán học trên công cụ tìm kiếm cho chiến lược nội dung của bạn. Nếu vector này không rõ ràng, Google sẽ khó xác định website có phải là nguồn đáng tin cậy để lập chỉ mục ưu tiên hay không.
2. Giao Thức WebMCP Và Sự Tin Cậy Của Tác Nhân AI
Google đã giới thiệu giao thức WebMCP vào năm 2026, cho phép các tác nhân AI (AI Agents) thực hiện các hành động có cấu trúc trực tiếp trên website thông qua API trình duyệt.
Chuẩn kết nối mới: Đây là tiêu chuẩn mở giúp xây dựng kết nối hai chiều an toàn giữa nguồn dữ liệu và công cụ AI.
Indexing cho AI: Việc tận dụng WebMCP đảm bảo cấu trúc trang web thân thiện với các trình thu thập AI, giúp nội dung không chỉ được index mà còn được các mô hình ngôn ngữ lớn (LLM) tin tưởng và trích dẫn.
3. Generative Engine Optimization (GEO) Và Vị Thế "Nguồn Kiến Thức Gốc"
Thành công SEO năm 2026 không chỉ là xếp hạng thứ nhất, mà là trở thành nguồn tin cậy mà AI tham chiếu. Chiến lược GEO (Generative Engine Optimization) tập trung vào việc định hình môi trường thông tin để máy móc hiểu thương hiệu theo cách bạn muốn.
Moat dữ liệu độc quyền: Dữ liệu nghiên cứu nguyên bản và ý kiến chuyên gia (Experience) trở thành "hào bẫy" bảo vệ website khỏi sự đào thải của nội dung AI đại trà.
Đo lường mới: Thay vì chỉ theo dõi click, các thương hiệu cần đo lường "AI Share of Voice" (Tỷ lệ xuất hiện trong câu trả lời AI) và traffic từ các nền tảng LLM.
4. Hệ Thống Cập Nhật Lõi 2026: Ưu Tiên Trải Nghiệm Thực Tế
Từ tháng 1 đến tháng 3 năm 2026, Google liên tục tinh chỉnh các tín hiệu chất lượng thông qua các bản cập nhật Core Update.
Sự lên ngôi của Experience: "Trải nghiệm" (Experience) đã trở thành yếu tố phân loại sơ cấp giữa nội dung chất lượng cao và nội dung từ các "trang trại AI" vô danh.
Nhận diện mẫu AI: Thuật toán hiện đại sử dụng mô hình AI tinh vi để phát hiện các mẫu viết lách thiếu tính xác thực, không nhất quán với các nguồn tham chiếu uy tín. Tấn Phát Digital nhấn mạnh việc sử dụng AI như công cụ hỗ trợ nhưng phải có sự biên tập và kiểm chứng từ chuyên gia thực thụ.
Case Study Thực Chiến 2026: Giải Quyết Nút Thắt Lập Chỉ Mục
Dưới đây là 10 trường hợp điển hình đã áp dụng các chiến lược của Tấn Phát Digital để khôi phục và thúc đẩy khả năng hiển thị:
Matt Diggity (SaaS SEO): Tăng trưởng 3.773% traffic trong 12 tháng bằng cách áp dụng "User-first content plan" và sử dụng Google Indexing API để thông báo lập chỉ mục tức thì ngay khi xuất bản bài viết mới.
BlueTally (Asset Management): Tăng trưởng 14.637% traffic (từ 52 lên 7.663 visitors) bằng cách tập trung vào các từ khóa có ý định mua hàng cao (high-intent) và xây dựng hệ thống hướng dẫn tích hợp chi tiết thay vì nội dung mỏng.
Bloom & Wild (Ecommerce): Tăng trưởng 472% traffic YoY nhờ chiến lược blog trả lời các câu hỏi cụ thể của người dùng về cách chăm sóc hoa, biến blog thành nguồn kéo 96% traffic tự nhiên của toàn trang.
Instatus (DevOps Tools): Tăng 1.500% traffic và 833% MRR (Doanh thu định kỳ hàng tháng) sau khi khắc phục triệt để các lỗi thu thập dữ liệu và tối ưu cấu trúc site cho các từ khóa ngách mà đối thủ lớn bỏ qua.
Picflow (AI Platform): Đạt mức tăng 525% tỷ lệ đăng ký từ blog bằng cách xây dựng các cụm chủ đề (topic clusters) xung quanh các tính năng chuyển đổi cao nhất của sản phẩm thay vì traffic đại trà.
UXCam (Mobile Analytics): Gần như gấp đôi traffic (9.300 lên 17.000) trong 6 tháng sau khi chuyển đổi từ nội dung chung chung sang nội dung lấy sản phẩm làm trung tâm (product-led content) và khắc phục các lỗi viết kém chất lượng.
Arnette (Gen Z Fashion): Tăng 11.4% số lần nhấp tự nhiên mà không cần thêm nội dung mới, chỉ bằng cách triển khai dữ liệu cấu trúc GS1 Web Vocabulary giúp Googlebot hiểu sâu hơn về đặc tính sản phẩm.
L’Oréal Turkey (Beauty): Tăng 147% số lần nhấp nhờ sử dụng AI và Knowledge Graphs để mở rộng quy mô SEO một cách tự động nhưng vẫn đảm bảo độ tin cậy và thực thể thương hiệu.
Quality Woven Labels (E-commerce): Tăng 118% doanh thu tự nhiên sau khi thực hiện kiểm toán kỹ thuật (Technical Audit), loại bỏ 41 phiên bản trang chủ trùng lặp trong sitemap và noindex hàng loạt trang đăng nhập vô dụng.
Retailer Nội Thất (Migration): Khôi phục 60% traffic sau khi di chuyển từ Magento sang Shopify bằng cách sửa lỗi chuỗi chuyển hướng (redirect chains) thành 301 trực tiếp và gỡ bỏ thẻ noindex bị bỏ quên trong môi trường staging.
Câu Hỏi Thường Gặp (FAQ) Về Lỗi Google Không Index
1. Sau khi sửa lỗi, mất bao lâu thì trang được index lại? Thời gian thường dao động từ vài ngày đến vài tuần tùy thuộc vào uy tín website. Quá trình xác thực lỗi (Validate Fix) có thể kéo dài tới 2 tuần hoặc lâu hơn.
2. Có cần xử lý hết tất cả URL trong nhóm Not Indexed (Xám) không? Không cần thiết. Bạn chỉ nên tập trung vào các trang quan trọng cần SEO. Các trang như lưu trữ (archives), tag, hoặc URL tham số thường không cần index.
3. "Soft 404" và "Not Found (404)" khác nhau như thế nào? 404 là mã trạng thái chuẩn khi trang không tồn tại. Soft 404 xảy ra khi server báo 200 OK (thành công) nhưng nội dung trang lại là báo lỗi hoặc trống rỗng.
4. Tại sao trang báo "Crawled – currently not indexed" dù nội dung tôi tự viết? Có thể Google đánh giá nội dung chưa đủ độc bản so với các kết quả hiện có hoặc website chưa đủ thẩm quyền chuyên môn (Topical Authority) trong lĩnh vực đó.
5. Lỗi "Discovered – currently not indexed" thường do đâu? Nguyên nhân phổ biến là do ngân sách thu thập dữ liệu bị hạn chế, máy chủ phản hồi chậm hoặc Google chưa ưu tiên trang này vì thiếu liên kết nội bộ.
6. Tôi có thể dùng Google Indexing API cho các bài blog thông thường không? Dù Google thông báo dành cho JobPosting và BroadcastEvent , nhưng thực tế các SEOer vẫn sử dụng thành công cho blog để đẩy nhanh tốc độ index.
7. Rank Math hay Yoast SEO tốt hơn cho việc lập chỉ mục năm 2026? Rank Math được đánh giá cao hơn về tính năng hỗ trợ lập chỉ mục tức thì (Instant Indexing) miễn phí và nhẹ hơn.
8. Tại sao trang bị chặn bởi Robots.txt vẫn xuất hiện trên kết quả tìm kiếm? Robots.txt chỉ ngăn Google "quét" (crawl) chứ không ngăn "hiển thị" (index) nếu có các liên kết bên ngoài trỏ về URL đó. Hãy dùng thẻ noindex để ngăn hiển thị triệt để.
9. "Redirect error" trong GSC nghĩa là gì? Đây là lỗi Googlebot không thể đến được URL cuối cùng do chuỗi chuyển hướng quá dài (hơn 10 bước) hoặc bị vòng lặp (A trỏ về B, B trỏ về A).
10. Core Web Vitals có ảnh hưởng trực tiếp đến việc index không? Có. Hiệu suất kém làm tiêu tốn crawl budget, khiến bot rời trang sớm và không kịp index các nội dung khác.
11. Cách kiểm tra nhanh nhất một URL đã được index hay chưa?
Sử dụng cú pháp site:URL-cần-kiểm-tra trên Google Search hoặc dùng công cụ "Kiểm tra URL" trong GSC.
12. Xu hướng SGE (AI tìm kiếm) ảnh hưởng thế nào đến việc lập chỉ mục?
AI ưu tiên trích dẫn các nguồn tin cậy, có dữ liệu cấu trúc (Schema) rõ ràng và nội dung giải quyết trực tiếp vấn đề của người dùng.
13. "Duplicate without user-selected canonical" là gì? Nghĩa là trang bị trùng lặp nội dung nhưng bạn chưa khai báo thẻ chính tắc (canonical), dẫn đến Google phải tự chọn một bản để index.
14. Tôi nên làm gì nếu quá trình "Validate Fix" báo thất bại? Kiểm tra URL cụ thể gây lỗi trong báo cáo chi tiết, sửa lại và khởi động lại quá trình xác thực.
15. Làm sao để tăng ngân sách thu thập dữ liệu (Crawl Budget)? Nâng cấp máy chủ, xây dựng liên kết nội bộ mạnh mẽ và loại bỏ (noindex) các trang rác, trang chất lượng thấp trên web.
Để website luôn nằm trong nhóm "Đã lập chỉ mục", bạn nên thực hiện kiểm tra định kỳ hàng tuần. Hãy bắt đầu bằng việc chẩn đoán các trang lỗi trên GSC, sửa lỗi kỹ thuật, nâng cấp nội dung theo E-E-A-T và cuối cùng là kích hoạt yêu cầu lập chỉ mục lại. Sự kiên trì và thấu hiểu thuật toán sẽ là chìa khóa giúp website của bạn đứng vững trước những thay đổi mang tính cách mạng của công nghệ tìm kiếm AI.
Việc xử lý lỗi Google không index đòi hỏi sự hiểu biết sâu sắc về kỹ thuật SEO và cơ chế hoạt động của Google. Bạn cần hiểu rõ cấu trúc URL trên website của mình, phân loại chính xác các trang nên index và không nên index, từ đó áp dụng giải pháp triệt để nhất. Đừng quá lo lắng về con số Not Indexed, hãy tập trung vào chất lượng của các trang cần thiết và đảm bảo chúng nằm trong nhóm Indexed.
Bạn đang gặp khó khăn trong việc xử lý các lỗi kỹ thuật phức tạp trên GSC và cần một giải pháp triệt để?
Tấn Phát Digital với kinh nghiệm chuyên sâu trong Technical SEO và Audit website sẽ giúp bạn:
Phân tích triệt để lỗi Not Indexed, xác định Root Cause.
Tối ưu hóa cấu trúc website và Crawl Budget.
Đảm bảo tốc độ và hiệu suất website đạt chuẩn Google.
Hãy liên hệ ngay với Tấn Phát Digital để được tư vấn và nhận giải pháp SEO toàn diện, giúp website của bạn luôn được Google Index và xếp hạng một cách tối ưu nhất!





![Hình ảnh đại diện của bài viết: [Series] Hỏi Chuyên Gia SEO — Kỳ 3: SEO Content hay AI Content — cái nào hiệu quả 2026](/_next/image?url=https%3A%2F%2Fcdn.tanphatdigital.com%2Fimages%2Fseries-hoi-chuyen-gia-seo-ky-3-seo-content-hay-ai-content-cai-nao-hieu-qua-2026.webp&w=1920&q=75)
![Hình ảnh đại diện của bài viết: [Series] Hỏi Chuyên Gia SEO — Kỳ 2: Chiến Lược Backlink Trong Kỷ Nguyên AI](/_next/image?url=https%3A%2F%2Fcdn.tanphatdigital.com%2Fimages%2Fseries-hoi-chuyen-gia-seo-ky-2-chien-luoc-backlink-trong-ky-nguyen-ai.webp&w=1920&q=75)