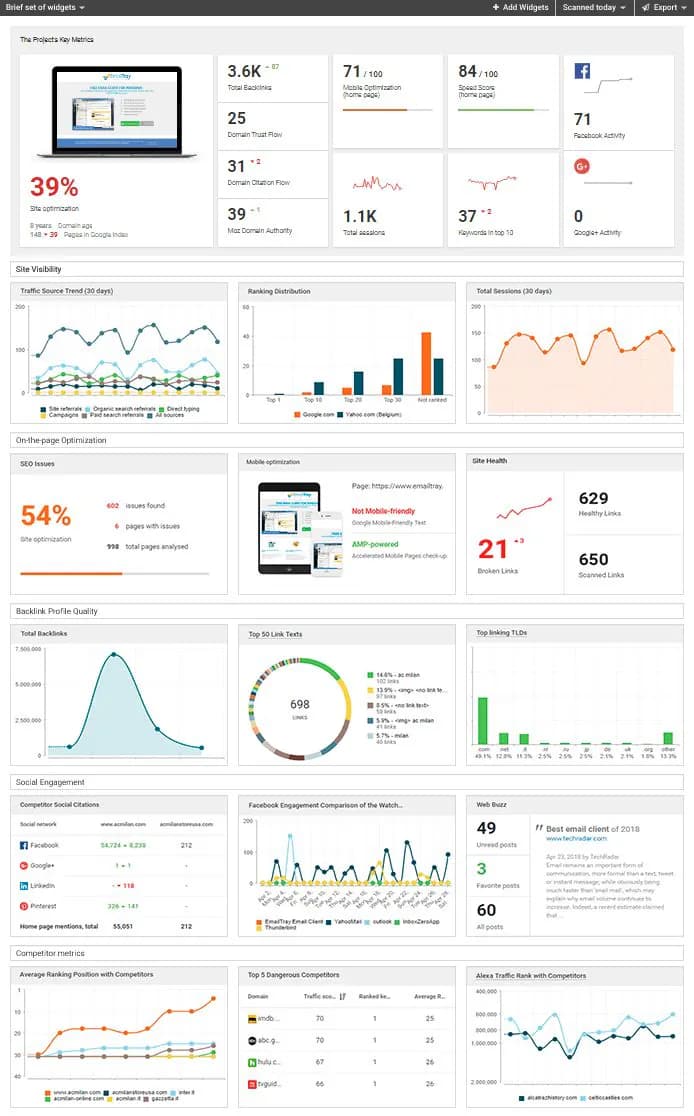
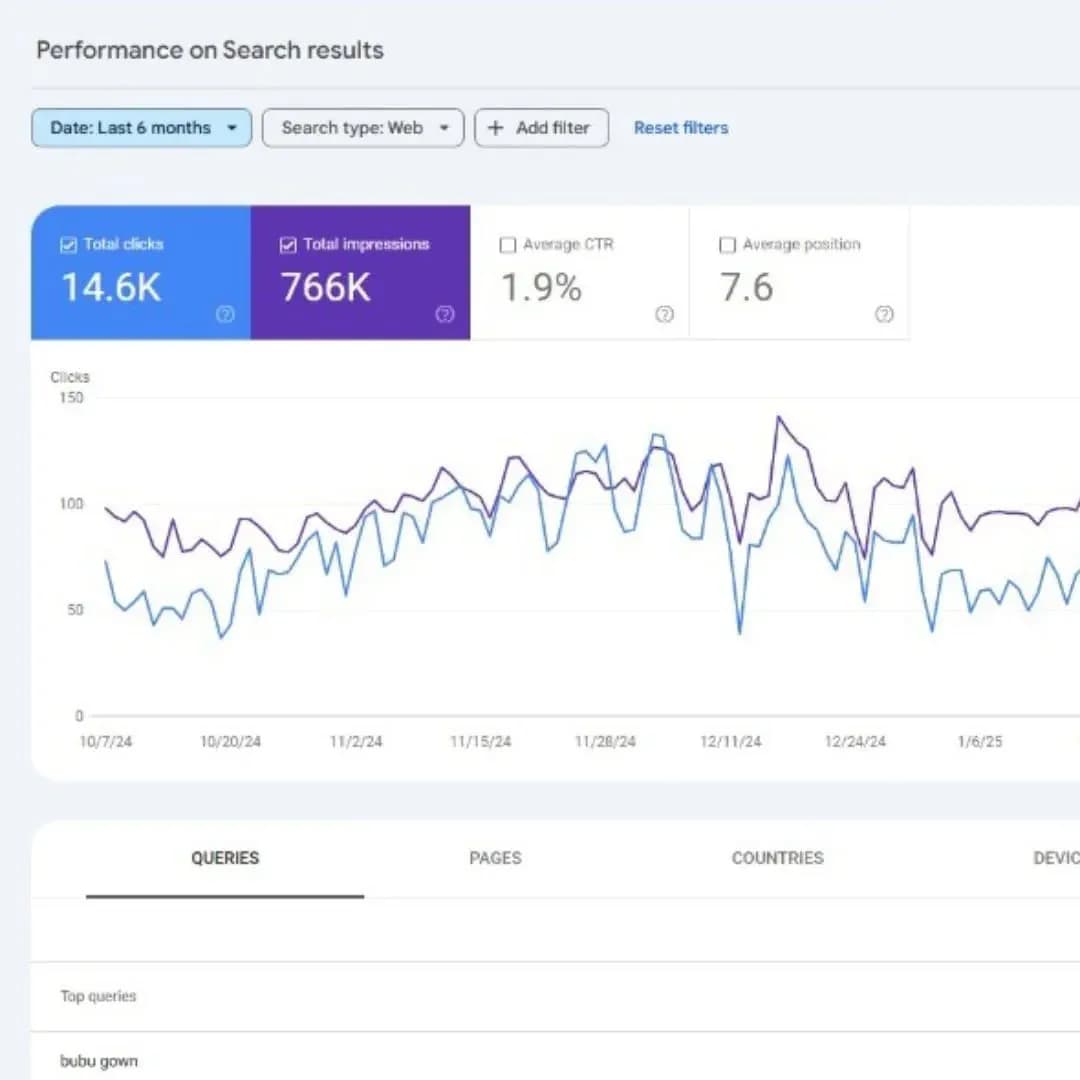
Tấn Phát Digital — Bài viết được biên dịch và Việt hóa từ tài liệu chính thức "Introduction to robots.txt" của Google Search Central. Đây là bài kỹ thuật chi tiết về file robots.txt — với code mẫu, best practices và cảnh báo những lỗi nguy hiểm.
File 1 KB có thể phá hủy toàn bộ SEO của bạn
Năm 2020, một website ecommerce lớn tại Việt Nam mất 95% traffic chỉ sau 1 đêm. Nguyên nhân? Developer push code lên production và quên xóa 1 dòng trong robots.txt:
User-agent: *
Disallow: /
1 dòng. 4 ký tự Disallow: /. Mất triệu USD doanh thu.
Đây là sức mạnh — và sự nguy hiểm — của file robots.txt. Một file nhỏ (thường <1 KB) nhưng có thể:
Cho phép hay chặn Google crawl toàn site
Quản lý crawl budget
Bảo vệ server khỏi overload
Direct Google đến sitemap
Nhưng cũng có thể:
Vô tình chặn toàn site
Vô tình expose nội dung nhạy cảm
Lãng phí crawl budget
Cản trở SEO
Bài viết này, Tấn Phát Digital sẽ giải mã toàn bộ về robots.txt — từ cơ bản đến advanced.
Bài viết này dành cho:
Developer quản lý website
Technical SEO chuyên về crawl/index
DevOps deploy production sites
Chủ website muốn hiểu để tránh rủi ro
Phần 1: Robots.txt là gì?
1.1. Định nghĩa từ Google
Google nói:
"File robots.txt tells search engine crawlers which URLs the crawler CAN ACCESS trên site bạn. Điều này được dùng chủ yếu để AVOID OVERLOADING site với requests; nó KHÔNG phải là mechanism để keep web page out of Google."
Đơn giản: robots.txt nói cho crawlers (như Googlebot) biết:
URL nào được phép crawl
URL nào không được crawl
1.2. ⚠️ MISCONCEPTION lớn nhất
Đây là điều 99% người Việt hiểu sai:
🚨 Robots.txt KHÔNG phải để ẨN trang khỏi Google!
Google nói rõ:
"Warning: DON'T use robots.txt file as means để HIDE web pages từ Google Search results."
Tại sao?
Google explain:
"Nếu other pages POINT TO trang bạn với descriptive text, Google có thể STILL INDEX URL mà KHÔNG visiting page."
→ Trang có thể vẫn xuất hiện trong search results, chỉ là không có snippet/description.
1.3. Để ẩn trang đúng cách
Để THẬT SỰ chặn trang khỏi Google:
Meta noindex:
<meta name="robots" content="noindex">
HTTP header:
X-Robots-Tag: noindex
Password protection:
AuthType Basic
AuthName "Restricted"
AuthUserFile /path/.htpasswd
Require valid-user
Remove URL trong Search Console
Xem thêm: Công cụ tạo Robots.txt Generator - Tạo File Robots.txt
Phần 2: Robots.txt dùng cho gì?
Google phân biệt 3 use cases chính theo loại file:
2.1. Web Pages (HTML, PDF...)
Use case:
Manage crawl traffic (tránh server overload)
Avoid crawling unimportant pages
Avoid crawling similar pages
⚠️ KHÔNG dùng để:
Hide pages khỏi search results
Replace noindex
Replace password protection
Ví dụ:
# Tránh crawl filter combinations vô tận
User-agent: *
Disallow: /search/
Disallow: /*?filter=
Disallow: /*&sort=
2.2. Media Files (Images, Videos, Audio)
Use case:
Manage crawl traffic
CÓ THỂ prevent images/videos xuất hiện trong Google Search
Ví dụ:
# Chặn ảnh khỏi Google Images
User-agent: Googlebot-Image
Disallow: /private-photos/
# Chặn video khỏi Google Video
User-agent: Googlebot-Video
Disallow: /private-videos/
⚠️ Lưu ý: Không prevent users hoặc other sites link đến file.
2.3. Resource Files (CSS, JS, Images cho rendering)
Google cảnh báo:
"Nếu absence of these resources làm page HARDER cho Google's crawler để understand, DON'T BLOCK them."
🚨 CẢNH BÁO: Đừng block CSS/JS resources!
# SAI - sẽ làm Google không render được page đúng
User-agent: Googlebot
Disallow: /css/
Disallow: /js/
→ Google sẽ thấy "trang trần trụi" và đánh giá kém.
Phần 3: Cú pháp robots.txt
3.1. Cấu trúc cơ bản
User-agent: [crawler name]
[Directive]: [URL pattern]
[Directive]: [URL pattern]
User-agent: [another crawler]
[Directive]: [URL pattern]
3.2. Các directives chính
User-agent
Specify crawler nào sẽ follow rules:
User-agent: * # Áp dụng cho TẤT CẢ crawlers
User-agent: Googlebot # Chỉ Googlebot
User-agent: Bingbot # Chỉ Bingbot
User-agent: AhrefsBot # Chỉ Ahrefs crawler
Các Google bots phổ biến:
Bot | Mục đích |
|---|---|
| Web crawler chính |
| Hình ảnh |
| Video |
| Tin tức |
| AdSense |
| Google Ads |
| Mobile crawler |
Disallow
Chặn crawl:
Disallow: / # Chặn TẤT CẢ
Disallow: /admin/ # Chặn folder /admin/
Disallow: /private.html # Chặn file cụ thể
Disallow: /*?sort= # Chặn URLs có ?sort=
Disallow: /*.pdf$ # Chặn tất cả .pdf
Allow
Cho phép crawl (override Disallow):
Disallow: /admin/
Allow: /admin/public/ # Allow này override Disallow
Sitemap
Direct đến sitemap:
Sitemap: https://example.com/sitemap.xml
Sitemap: https://example.com/sitemap-products.xml
→ Có thể có nhiều dòng Sitemap.
3.3. Wildcards
* — Match bất kỳ ký tự nào:
Disallow: /*.pdf # Chặn mọi .pdf
Disallow: /*?utm_source= # Chặn UTM tracking
Disallow: /tmp-* # Chặn folder bắt đầu bằng tmp-
$ — Match cuối URL:
Disallow: /*.pdf$ # CHỈ chặn URLs kết thúc bằng .pdf
# /page.pdf → blocked
# /page.pdf?ref=fb → NOT blocked
3.4. Comments
Bắt đầu bằng #:
# Đây là comment - không ảnh hưởng rules
User-agent: *
Disallow: /admin/ # Chặn admin area
Phần 4: Robots.txt templates cho các tình huống
4.1. Template 1: Allow ALL (mặc định an toàn nhất)
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml
→ Cho phép crawl mọi thứ. Phù hợp với hầu hết website.
4.2. Template 2: Disallow ALL (Block hoàn toàn)
User-agent: *
Disallow: /
⚠️ CẢNH BÁO: Dùng CỰC KỲ thận trọng. Chỉ dùng:
Site đang dev/staging
Tạm thời maintenance
Site internal không muốn public
4.3. Template 3: WordPress chuẩn
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /readme.html
Disallow: /xmlrpc.php
Disallow: /trackback/
Disallow: /feed/
Disallow: /*?replytocom=
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap_index.xml
4.4. Template 4: Ecommerce
User-agent: *
# Chặn admin và account areas
Disallow: /admin/
Disallow: /account/
Disallow: /checkout/
Disallow: /cart/
# Chặn search/filter combinations vô tận
Disallow: /search?
Disallow: /*?sort=
Disallow: /*?filter=
Disallow: /*&sort=
Disallow: /*&filter=
# Chặn tracking parameters
Disallow: /*?utm_*
Disallow: /*&utm_*
Disallow: /*?fbclid=
Disallow: /*?gclid=
# Allow important pages
Allow: /san-pham/
Allow: /danh-muc/
Sitemap: https://shop.com/sitemap.xml
Sitemap: https://shop.com/sitemap-products.xml
4.5. Template 5: Multi-language site
User-agent: *
Allow: /
# Chặn admin
Disallow: /admin/
# Sitemap riêng cho mỗi ngôn ngữ
Sitemap: https://example.com/sitemap-vi.xml
Sitemap: https://example.com/sitemap-en.xml
Sitemap: https://example.com/sitemap-ja.xml
4.6. Template 6: Chặn AI scrapers (mới 2024-2026)
User-agent: *
Allow: /
# Chặn AI training crawlers
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Google-Extended
Disallow: /
Sitemap: https://example.com/sitemap.xml
→ Block các bots dùng content cho AI training (không ảnh hưởng SEO của Google Search).
Phần 5: Best Practices
5.1. Vị trí file
Robots.txt PHẢI ở root của domain:
✅ Đúng:
https://example.com/robots.txt
❌ Sai:
https://example.com/folder/robots.txt
https://example.com/robots.txt.bak
5.2. UTF-8 encoding
# Tạo file robots.txt với UTF-8 encoding
# Không dùng BOM (Byte Order Mark)
5.3. Case-sensitive
URLs trong robots.txt CASE-SENSITIVE:
Disallow: /Admin/ # Chặn /Admin/ nhưng KHÔNG chặn /admin/
Disallow: /admin/ # Chặn /admin/ nhưng KHÔNG chặn /Admin/
→ Tốt nhất: Dùng lowercase nhất quán.
5.4. Test trước khi deploy
Dùng robots.txt Tester trong Search Console (legacy tool):
Search Console → Legacy tools
Robots Testing Tool
Test các URLs cụ thể
Hoặc dùng tools online:
5.5. Specific rules win
Khi conflict, specific rule thắng:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: / # Googlebot vẫn được crawl
5.6. Always include Sitemap
Sitemap: https://example.com/sitemap.xml
→ Best practice cho mọi robots.txt.
5.7. Keep it simple
❌ Sai: Robots.txt 200 dòng phức tạp
✅ Đúng: Tối thiểu cần thiết, comments rõ ràng
Phần 6: 10 SAI LẦM CHẾT NGƯỜI cần tránh
❌ Sai lầm 1: Disallow / trên production
User-agent: *
Disallow: /
Hậu quả: TOÀN BỘ site bị chặn crawl.
Phòng tránh: Checklist deploy + test ngay sau deploy.
❌ Sai lầm 2: Block CSS/JS
User-agent: Googlebot
Disallow: /css/
Disallow: /js/
Hậu quả: Google không render đúng → ranking giảm.
Đúng: Allow CSS/JS cho Googlebot.
❌ Sai lầm 3: Dùng robots.txt để hide content
Disallow: /private-data/
Hậu quả:
URL vẫn xuất hiện trong search (không có description)
Người khác có thể đọc robots.txt → biết bạn có
/private-data/Không thực sự bảo vệ data
Đúng: Password protection + noindex.
❌ Sai lầm 4: Quên Sitemap directive
Hậu quả: Google khó tìm sitemap.
Đúng: Luôn include Sitemap:.
❌ Sai lầm 5: Đặt file sai vị trí
https://example.com/folder/robots.txt ← SAI
Hậu quả: Google không tìm thấy.
Đúng: Luôn ở root.
❌ Sai lầm 6: Block sitemap trong robots.txt
Disallow: /sitemap.xml
Hậu quả: Google không crawl được sitemap.
Đúng: Đừng chặn sitemap.
❌ Sai lầm 7: Conflict rules không nhất quán
Disallow: /admin/
Allow: /admin/
Hậu quả: Behavior không predictable.
Đúng: Rules rõ ràng, không mâu thuẫn.
❌ Sai lầm 8: Block images quan trọng
User-agent: Googlebot-Image
Disallow: /
Hậu quả: Mất traffic từ Google Images.
Đúng: Chỉ block ảnh không muốn xuất hiện.
❌ Sai lầm 9: Block tracking parameters quá rộng
Disallow: /*?
Hậu quả: Chặn TẤT CẢ URLs có query parameters (bao gồm cả URL hợp lệ).
Đúng: Chặn specific parameters:
Disallow: /*?utm_
Disallow: /*?fbclid=
❌ Sai lầm 10: Quên test sau deploy
Hậu quả: Không phát hiện vấn đề kịp thời.
Đúng: Test ngay sau mỗi thay đổi.
Phần 7: Limitations của Robots.txt
Google liệt kê 3 limitations quan trọng:
Limitation 1: Không phải mọi crawler tuân thủ
"Instructions trong robots.txt CANNOT ENFORCE crawler behavior; it's up to crawler để obey them."
Crawlers tốt (tuân thủ):
Googlebot ✅
Bingbot ✅
DuckDuckBot ✅
Crawlers xấu (có thể ignore):
Spam bots
Scraping bots
Một số AI scrapers
→ Robots.txt KHÔNG bảo vệ content khỏi bots xấu.
Limitation 2: Crawlers interpret khác nhau
"Each crawler might interpret rules DIFFERENTLY."
→ Cần test với từng search engine quan trọng.
Limitation 3: Disallowed pages có thể vẫn được indexed
"Page bị disallowed trong robots.txt có thể STILL BE INDEXED nếu linked từ other sites."
🚨 Như đã nói: Robots.txt KHÔNG đảm bảo trang không xuất hiện trong search.
Phần 8: Robots.txt cho các Platforms
8.1. WordPress
WordPress mặc định có robots.txt động (virtual). Để custom:
Cách 1: Plugin (Yoast SEO/Rank Math)
Vào plugin → Tools → File editor → robots.txt
Cách 2: Tạo file vật lý
Tạo robots.txt ở root WordPress.
8.2. Shopify
Shopify có robots.txt mặc định. Customize qua Online Store → Themes → Edit code → robots.txt.liquid:
{% for group in robots.default_groups %}
{{- group.user_agent }}
{%- for rule in group.rules -%}
{{ rule }}
{%- endfor -%}
{%- if group.sitemap != blank -%}
{{ group.sitemap }}
{%- endif -%}
{% endfor %}
# Custom rules
User-agent: GPTBot
Disallow: /
8.3. Next.js
Tạo public/robots.txt:
User-agent: *
Allow: /
Disallow: /api/
Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
8.4. Custom server (Nginx)
location = /robots.txt {
add_header Content-Type text/plain;
return 200 "User-agent: *\nAllow: /\n\nSitemap: https://example.com/sitemap.xml\n";
}
Phần 9: Monitoring Robots.txt
9.1. Search Console
Robots.txt Tester (Legacy):
Test changes trước khi deploy
Validate syntax
Test specific URLs
Crawl Stats (Settings → Crawl Stats):
Xem Google fetch robots.txt khi nào
Detect issues
9.2. Server logs
# Xem requests đến robots.txt
grep "robots.txt" /var/log/nginx/access.log | tail -20
→ Google thường fetch robots.txt mỗi 24h.
9.3. External tools
Screaming Frog — Test robots.txt impact
TechnicalSEO.com — Online tester
Sitebulb — Comprehensive audit
Phần 10: Checklist Robots.txt
Pre-deployment
[ ] File ở root domain
[ ] UTF-8 encoding
[ ] No BOM
[ ] Lowercase URLs consistency
[ ] No syntax errors
[ ] Include Sitemap directive
[ ] Comments rõ ràng
Validation
[ ] Test với Robots.txt Tester
[ ] Test multiple URLs (cả allowed + disallowed)
[ ] Verify CSS/JS không bị block
[ ] Verify important pages không bị block
Production
[ ] Deploy careful
[ ] Test ngay sau deploy
[ ] Monitor Search Console 24h
[ ] Check crawl stats
Kết luận
Robots.txt là file nhỏ nhưng sức mạnh khổng lồ. Một dòng sai có thể phá hủy toàn bộ SEO. Một setup đúng có thể tối ưu crawl budget hiệu quả.
5 thông điệp cuối
1. KHÔNG dùng robots.txt để hide. Dùng noindex hoặc password protection.
2. KHÔNG block CSS/JS. Google cần để render.
3. ALWAYS include Sitemap. Best practice.
4. TEST ngay sau deploy. Catch errors sớm.
5. KEEP IT SIMPLE. Đơn giản, rõ ràng, có comments.
Tài liệu tham khảo
Về Tấn Phát Digital
Tấn Phát Digital triển khai robots.txt strategy cho:
Site lớn với crawl budget hạn chế
Ecommerce với faceted navigation
Multi-language sites
Recovery sites sau robots.txt errors
Liên hệ để optimize robots.txt cho site của bạn.
Biên soạn từ Google Search Central, 10/12/2025. Code samples và best practices thuộc về Tấn Phát Digital.
Robots.txt là nền tảng quan trọng trong chiến lược Technical SEO và quản lý crawl website hiệu quả.
Nếu bạn muốn tối ưu Technical SEO và xây dựng website chuẩn Google, hãy liên hệ Tấn Phát Digital để được tư vấn.