Tấn Phát Digital — Bài viết được biên dịch, phân tích chuyên sâu và Việt hóa từ tài liệu chính thức "In-depth guide to how Google Search works" của Google Search Central. Đây là bài viết nền tảng quan trọng nhất — hiểu được cách Google hoạt động, bạn sẽ hiểu mọi vấn đề SEO đều có giải pháp logic.
Tại sao bạn PHẢI hiểu cách Google Search hoạt động?
Có một câu nói nổi tiếng trong giới SEO:
"Bạn không thể tối ưu cho một hệ thống mà bạn không hiểu cách nó hoạt động."
Tại Việt Nam, rất nhiều người làm SEO theo kiểu "truyền miệng" — học các "thủ thuật" mà không hiểu tại sao chúng hoạt động. Khi Google update, họ hoang mang vì không biết phải làm gì.
Ngược lại, nếu bạn hiểu rõ cơ chế hoạt động của Google Search, bạn sẽ:
Tự chẩn đoán được mọi vấn đề SEO
Dự đoán được ảnh hưởng của các thay đổi trên website
Không bị lừa bởi các "thủ thuật SEO" sai
Đưa ra quyết định đúng mà không cần copy ai khác
Bài viết này sẽ giải mã 3 giai đoạn cốt lõi của Google Search theo tài liệu chính thức, kèm phân tích sâu và ví dụ thực tế cho thị trường Việt Nam.
Bài viết này dành cho:
Người mới làm SEO — cần kiến thức nền tảng vững chắc
Marketing Manager — hiểu để giao việc cho team đúng
Chủ doanh nghiệp — biết kiểm soát SEO của mình
Developer — hiểu để build website tốt hơn
Bất kỳ ai muốn website xuất hiện trên Google
Phần 1: Bức tranh toàn cảnh — Google Search là gì?
1.1. Định nghĩa từ Google
Google mở đầu tài liệu rất rõ ràng:
"Google Search là một search engine hoàn toàn tự động, sử dụng phần mềm gọi là web crawler để khám phá web thường xuyên, tìm các trang để thêm vào index của chúng tôi."
3 từ khóa cần lưu ý:
"Fully-automated" — Hoàn toàn tự động
"Web crawler" — Phần mềm bò qua các trang web
"Index" — Cơ sở dữ liệu khổng lồ lưu trữ thông tin
1.2. Một sự thật quan trọng
Google nhấn mạnh:
"Phần lớn các trang được liệt kê trong kết quả của chúng tôi KHÔNG được submit thủ công, mà được tìm thấy và thêm tự động khi web crawler khám phá web."
→ Điều này có nghĩa: Bạn không cần submit thủ công mọi trang cho Google. Nếu website của bạn có cấu trúc tốt, Google sẽ tự tìm thấy.
1.3. Cảnh báo quan trọng từ Google (lặp lại 2 lần trong tài liệu)
Lần 1 — Ở phần mở đầu:
"Google KHÔNG nhận tiền để crawl một site thường xuyên hơn, hoặc rank nó cao hơn. Nếu ai đó nói với bạn điều ngược lại, họ đang nói sai."
Lần 2 — Ở phần Serving:
"Google KHÔNG nhận tiền để rank trang cao hơn, và ranking được thực hiện theo lập trình (programmatically)."
→ Đây là vũ khí của bạn chống lại các agency SEO lừa đảo. Nếu ai nói có "mối quan hệ đặc biệt với Google" — họ đang lừa bạn.
1.4. Một sự thật cần chấp nhận
Google cũng thẳng thắn nói:
"Google KHÔNG đảm bảo sẽ crawl, index, hoặc serve trang của bạn, dù trang đó tuân thủ Google Search Essentials."
→ SEO không có gì là "đảm bảo". Bạn chỉ có thể tối đa hóa xác suất thành công bằng cách làm đúng.
Phần 2: Tổng quan 3 giai đoạn của Google Search
Đây là kiến thức CỐT LÕI của bài viết. Google Search hoạt động qua 3 giai đoạn, và không phải trang nào cũng vượt qua được mỗi giai đoạn.
Sơ đồ tổng quan
┌─────────────────────────────────────────────────────────┐
│ Giai đoạn 1: CRAWLING (Thu thập) │
│ Google tải xuống text, hình ảnh, video │
│ từ các trang tìm thấy trên internet │
└───────────────────┬─────────────────────────────────────┘
│
▼ (Không phải mọi trang đều qua được)
┌─────────────────────────────────────────────────────────┐
│ Giai đoạn 2: INDEXING (Lập chỉ mục) │
│ Google phân tích, xử lý và lưu trữ thông tin │
│ vào Google index — một database khổng lồ │
└───────────────────┬─────────────────────────────────────┘
│
▼ (Không phải mọi trang được index đều xuất hiện)
┌─────────────────────────────────────────────────────────┐
│ Giai đoạn 3: SERVING (Phục vụ kết quả) │
│ Khi user search, Google trả về kết quả │
│ liên quan và chất lượng cao nhất │
└─────────────────────────────────────────────────────────┘
Một điểm CỰC KỲ quan trọng
Mỗi giai đoạn là một "phễu" — trang có thể bị rớt ở bất kỳ giai đoạn nào:
Crawl được nhưng không index → trang không tồn tại trên Google
Index được nhưng không serve → trang có trên Google nhưng không hiển thị cho user
Hiểu điều này, bạn sẽ biết chính xác vấn đề của website ở đâu khi gặp lỗi SEO.
Phần 3: Giai đoạn 1 — CRAWLING (Thu thập)
3.1. Mục đích của giai đoạn Crawling
"Giai đoạn đầu tiên là tìm ra các trang nào tồn tại trên web."
Google nói thẳng:
"KHÔNG có một registry trung tâm cho tất cả các trang web, nên Google phải LIÊN TỤC tìm kiếm các trang mới và cập nhật để thêm vào danh sách các trang đã biết."
Quá trình này gọi là "URL Discovery" (Khám phá URL).
3.2. 3 cách Google tìm thấy URL mới
Cách 1: Đã ghé thăm trước đó
Google đã biết về trang vì nó đã crawl trang đó trước đây. Khi crawl lại, có thể có link mới trên trang dẫn đến URL khác.
Cách 2: Link từ trang đã biết
Đây là cách phổ biến nhất. Google tìm trang mới bằng cách:
Theo link từ trang đã crawl
Ví dụ: Trang hub (như danh mục blog) link đến một bài blog post mới
Ý nghĩa thực tế: Đây là lý do internal linking quan trọng — nó là "con đường" để Google tìm thấy nội dung mới trên website của bạn.
Cách 3: Bạn submit sitemap
Bạn chủ động gửi danh sách các trang qua XML sitemap.
→ Đặc biệt quan trọng cho:
Website mới chưa có backlink
Trang sâu trong cấu trúc, ít link nội bộ
Trang nội dung mới cần index nhanh
3.3. Googlebot là ai?
Sau khi tìm thấy URL, Google sẽ ghé thăm (crawl) trang để xem nội dung. Chương trình thực hiện việc này gọi là Googlebot.
Các tên gọi khác của Googlebot:
Crawler
Robot
Bot
Spider
Quy mô:
"Chúng tôi sử dụng một tập hợp máy tính khổng lồ để crawl hàng tỷ trang trên web."
Một số fact thú vị về Googlebot:
Hoạt động 24/7
Có nhiều biến thể (mobile crawler, desktop crawler, image bot, video bot, news bot...)
Dùng phiên bản Chrome mới nhất để render
Tôn trọng robots.txt
Tự điều chỉnh tốc độ để không "phá" server
3.4. Thuật toán quyết định crawl
Google nói:
"Googlebot sử dụng quy trình thuật toán để xác định: site nào để crawl, tần suất bao nhiêu, và số trang fetch từ mỗi site."
3 yếu tố Google quyết định:
Yếu tố | Ý nghĩa | Ảnh hưởng |
|---|---|---|
Site nào để crawl | Crawl site A vs site B | Site uy tín được crawl nhiều hơn |
Tần suất crawl | Mỗi giờ? Mỗi ngày? | Site cập nhật thường xuyên được crawl thường xuyên |
Số trang fetch | 100 trang hay 10,000 trang | Site lớn được crawl nhiều trang hơn — gọi là crawl budget |
3.5. Cơ chế tự bảo vệ — Không "phá" server
Đây là điểm rất hay mà ít người biết:
"Crawler của Google được lập trình sao cho cố gắng không crawl site quá nhanh để tránh quá tải. Cơ chế này dựa trên responses của site (ví dụ: HTTP 500 errors có nghĩa là 'slow down')."
Điều này có nghĩa:
Nếu server bạn trả về 5xx errors → Googlebot tự giảm tốc độ crawl
Nếu server bạn chậm → Googlebot crawl chậm hơn
Nếu response time quá lâu → Googlebot bỏ qua nhiều trang
→ Hậu quả: Server kém = ít trang được crawl = ít trang được index = ít traffic.
💡 Mẹo từ Tấn Phát Digital: Tốc độ server không chỉ quan trọng cho UX và Core Web Vitals — nó còn ảnh hưởng trực tiếp đến crawl budget.
3.6. Không phải mọi trang đều được crawl
Google nói rõ:
"Tuy nhiên, Googlebot không crawl tất cả các trang nó phát hiện."
Lý do trang không được crawl:
Bị disallow trong robots.txt — Bạn chủ động chặn
Cần đăng nhập — Googlebot không có credential
Bị orphan — Không có link nào dẫn đến
Server lỗi — Trả về 5xx khi Googlebot gọi
Crawl budget hạn chế — Site quá lớn, Google ưu tiên trang quan trọng
3.7. Rendering — Bước CỰC KỲ quan trọng cho website hiện đại
Đây là phần mà nhiều developer Việt Nam không biết hoặc hiểu sai.
"Trong quá trình crawl, Google RENDER trang và chạy bất kỳ JavaScript nào nó tìm thấy, sử dụng phiên bản gần đây của Chrome, tương tự như cách trình duyệt của bạn render các trang bạn ghé thăm."
Tại sao rendering quan trọng?
"Rendering quan trọng vì các website thường dựa vào JavaScript để đưa content lên trang, và KHÔNG có rendering, Google có thể KHÔNG THẤY nội dung đó."
Quy trình rendering 2 bước của Google:
Bước 1: Initial Crawl (HTML)
└─> Google fetch HTML raw, đọc các link
└─> Nếu HTML đã có đủ content → có thể index ngay
Bước 2: Rendering Queue (Render JavaScript)
└─> Trang được đưa vào queue chờ render
└─> Có thể mất vài giờ đến vài ngày
└─> Sau khi render xong → Google "thấy" nội dung JS
Ý nghĩa cho website React, Vue, Angular SPA:
Nếu nội dung quan trọng load qua JS → có thể chờ vài ngày mới được index
Nếu JS lỗi → Google không thấy nội dung
Server-Side Rendering (SSR) hoặc Static Site Generation (SSG) giúp nội dung xuất hiện trong HTML ban đầu → được index ngay
3.8. 3 vấn đề phổ biến khiến Googlebot không access được site
Google liệt kê:
Vấn đề | Nguyên nhân | Cách khắc phục |
|---|---|---|
Server lỗi | Server crash, quá tải, code lỗi | Monitor server, scale up, fix bugs |
Network issues | DNS sai, firewall block, IP block | Check DNS, whitelist Googlebot IP |
robots.txt block | Disallow trong robots.txt | Review robots.txt, mở các trang cần crawl |
3.9. Cách kiểm tra Googlebot có crawl được site bạn không
Cách 1: Server logs
# Nginx
grep "Googlebot" /var/log/nginx/access.log | tail -50
# Apache
grep "Googlebot" /var/log/apache2/access.log | tail -50
Cách 2: Google Search Console
Vào Settings → Crawl stats
Xem số request/ngày của Googlebot
Phát hiện các spike bất thường hoặc giảm đột ngột
Cách 3: URL Inspection Tool
Nhập URL cần kiểm tra
Click "Test live URL"
Xem screenshot và HTML mà Google thấy
Phần 4: Giai đoạn 2 — INDEXING (Lập chỉ mục)
4.1. Mục đích của giai đoạn Indexing
"Sau khi một trang được crawl, Google cố gắng HIỂU trang đó nói về điều gì."
Đây là bước Google chuyển từ "đọc" sang "hiểu". Cụ thể, Google:
Xử lý và phân tích nội dung văn bản
Phân tích các content tags và attributes quan trọng
Hiểu cấu trúc trang
4.2. Các yếu tố Google phân tích trong giai đoạn Indexing
Google liệt kê các yếu tố quan trọng:
Thẻ
<title>— Tiêu đề trang (xuất hiện trong tab browser và kết quả tìm kiếm)Alt attributes — Văn bản thay thế cho hình ảnh
Hình ảnh — Nội dung visual
Video — Nội dung video
Và nhiều yếu tố khác
Code minh họa các yếu tố quan trọng:
<!DOCTYPE html>
<html lang="vi">
<head>
<!-- Title - Quan trọng nhất -->
<title>Áo thun nam cotton trắng - Shop XYZ</title>
<!-- Meta description -->
<meta name="description" content="Áo thun nam cotton 100%, form regular...">
<!-- Canonical - Quan trọng cho duplicate content -->
<link rel="canonical" href="https://shop.com/ao-thun-nam-trang">
</head>
<body>
<!-- Heading - Phân cấp nội dung -->
<h1>Áo thun nam cotton trắng</h1>
<!-- Hình ảnh với alt text -->
<img src="ao-trang.jpg" alt="Áo thun nam cotton trắng, dáng regular fit">
<!-- Nội dung văn bản -->
<p>Mô tả chi tiết sản phẩm...</p>
<!-- Structured data -->
<script type="application/ld+json">
{ "@type": "Product", ... }
</script>
</body>
</html>
4.3. Xác định Canonical — Quy trình quan trọng
Đây là một trong những phần phức tạp nhất nhưng quan trọng nhất:
"Trong quá trình indexing, Google xác định xem một trang có phải là duplicate của trang khác trên internet hay là canonical."
Canonical là gì?
"Canonical là trang có thể được hiển thị trong kết quả tìm kiếm."
4.4. Quy trình chọn Canonical của Google
Google giải thích quy trình 2 bước:
Bước 1: Clustering (Gom nhóm)
"Trước tiên, chúng tôi nhóm các trang lại (gọi là clustering) — các trang chúng tôi tìm thấy trên internet có nội dung tương tự."
Ví dụ thực tế:
Bạn có một sản phẩm áo thun trắng. Các URL có thể xuất hiện:
https://shop.com/ao-thun-trang
https://shop.com/ao-thun-trang?color=white
https://shop.com/ao-thun-trang?utm_source=facebook
https://www.shop.com/ao-thun-trang
https://shop.com/ao-thun-trang/
http://shop.com/ao-thun-trang
→ Google sẽ gom nhóm tất cả URL này thành 1 cluster.
Bước 2: Select Representative (Chọn đại diện)
"Sau đó chúng tôi chọn trang đại diện nhất của nhóm."
Trang được chọn = Canonical.
Các trang còn lại = Alternate versions (có thể được hiển thị trong các context khác, ví dụ: mobile, hoặc khi user search rất cụ thể).
4.5. Các signal Google thu thập về Canonical
Google nói:
"Google cũng thu thập signals về canonical page và nội dung của nó, có thể được sử dụng ở giai đoạn tiếp theo (serving)."
Một số signals quan trọng:
Signal | Ý nghĩa | Cách Google xác định |
|---|---|---|
Language | Ngôn ngữ trang | HTML |
Country/locale | Quốc gia/khu vực | Domain (.vn), hreflang, server location |
Usability | Khả năng dùng được | Mobile-friendly, Core Web Vitals |
Topic | Chủ đề | Phân tích semantic của nội dung |
Quality | Chất lượng | E-E-A-T, helpful content, originality |
4.6. Google Index — Database khổng lồ
"Thông tin thu thập về canonical page và cluster của nó có thể được lưu trữ trong Google index, một database lớn host trên hàng nghìn máy tính."
Một số fact về Google Index:
Hàng trăm tỷ trang được lưu
Dung lượng hàng hàng trăm petabyte
Phân tán trên hàng nghìn data center trên toàn thế giới
Được cập nhật liên tục 24/7
4.7. Sự thật phũ phàng — Indexing KHÔNG đảm bảo
Google nói thẳng:
"Indexing KHÔNG được đảm bảo; không phải mọi trang Google xử lý đều được index."
→ Đây là lý do bạn thường thấy báo cáo Search Console: "Crawled - currently not indexed" hoặc "Discovered - currently not indexed".
4.8. 3 vấn đề phổ biến khiến trang không được index
Google liệt kê:
Vấn đề 1: Chất lượng nội dung thấp
Nếu nội dung:
Thin content (quá ít, không có giá trị)
Trùng lặp với hàng triệu trang khác
Tạo bằng AI hàng loạt không có giá trị gia tăng
Spam, không đáng tin
→ Google chọn KHÔNG index.
Vấn đề 2: Robots meta rules disallow indexing
<!-- Trang này NÓI Google không index -->
<meta name="robots" content="noindex">
Đôi khi do lỗi vô tình:
WordPress check vào "Discourage search engines" trong Settings
Theme/plugin tự thêm noindex
Developer copy code có noindex từ template
→ Luôn check meta robots khi trang không index.
Vấn đề 3: Thiết kế website gây khó khăn cho indexing
SPA không có SSR
Nội dung load qua JavaScript phức tạp
Cấu trúc URL kém
Không có internal linking
→ Refactor cấu trúc kỹ thuật.
Phần 5: Giai đoạn 3 — SERVING (Phục vụ kết quả tìm kiếm)
5.1. Khi user gõ một query
Đây là khoảnh khắc "magic" mà mọi người đều thấy hàng ngày:
"Khi user nhập một query, máy của chúng tôi tìm kiếm trong index các trang khớp và trả về các kết quả mà chúng tôi tin là chất lượng cao nhất và liên quan nhất đến query của user."
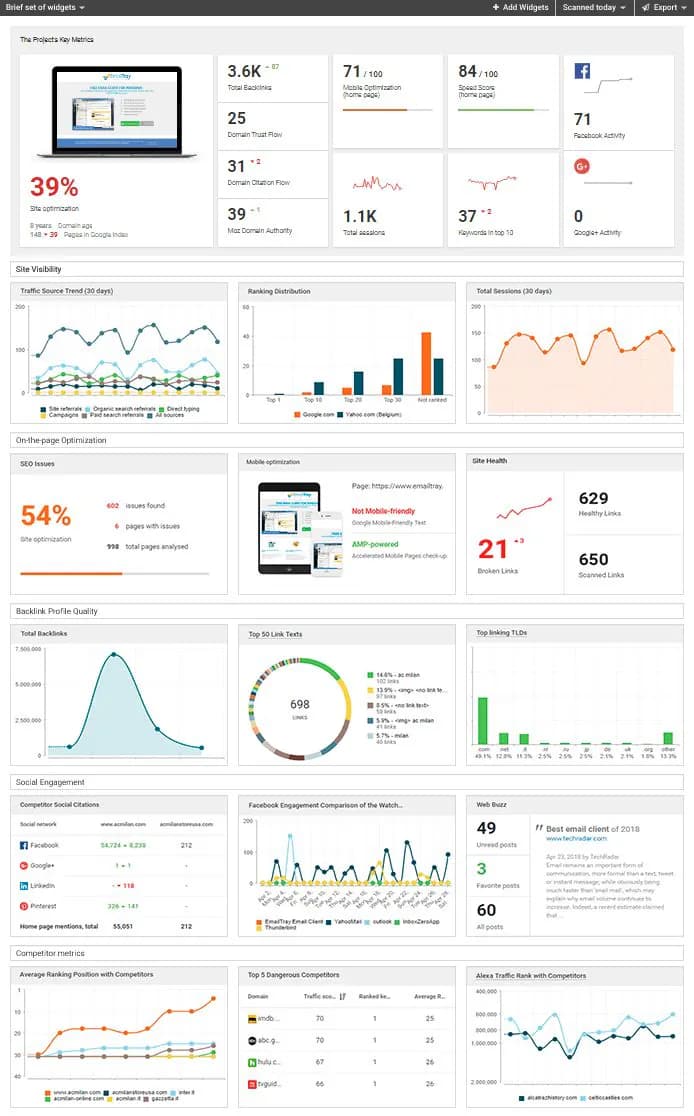
5.2. Hàng trăm yếu tố quyết định ranking
"Tính liên quan (Relevancy) được xác định bởi HÀNG TRĂM yếu tố."
Google không tiết lộ chính xác bao nhiêu yếu tố và cách tính trọng số, nhưng đề cập một số yếu tố quan trọng:
Yếu tố | Ảnh hưởng |
|---|---|
User location | Vị trí địa lý — quyết định kết quả local |
Language | Ngôn ngữ người dùng |
Device | Desktop hay mobile |
Search history | Lịch sử tìm kiếm (nếu đăng nhập) |
Time of day/year | Thời gian (kết quả khác nhau theo mùa) |
Query intent | Ý định của user (informational, navigational, transactional) |
Content quality | E-E-A-T, helpful content |
User signals | CTR, dwell time, bounce rate |
Page experience | Core Web Vitals, mobile-friendly |
Backlinks | Số lượng và chất lượng |
Freshness | Độ mới của nội dung |
5.3. Ví dụ điển hình từ Google — Cùng query, kết quả khác nhau
Google đưa ra ví dụ rất hay:
"Ví dụ: tìm kiếm 'bicycle repair shops' sẽ hiển thị các kết quả khác nhau cho user ở Paris so với user ở Hong Kong."
Áp dụng cho Việt Nam:
User ở Hà Nội search "quán phở ngon" → kết quả là các quán phở ở Hà Nội
User ở TP.HCM search cùng query → kết quả là các quán phở ở Sài Gòn
User ở Mỹ search → có thể là phở ở khu Việt Nam tại Mỹ
→ Đây là lý do Local SEO quan trọng với doanh nghiệp địa phương VN.
5.4. Search Features — Giao diện kết quả thay đổi theo query
Google nói:
"Dựa trên query của user, các search features xuất hiện trên trang kết quả tìm kiếm cũng thay đổi."
Ví dụ từ Google:
Search "bicycle repair shops" → Hiển thị local results (bản đồ + danh sách cửa hàng), không có image results
Search "modern bicycle" → Hiển thị image results, không có local results
Một số Search Features phổ biến:
Feature | Khi nào xuất hiện | Ví dụ |
|---|---|---|
Local Pack | Query có ý định local | "nhà hàng gần đây" |
Image Pack | Query về visual | "ảnh đẹp Đà Lạt" |
Video Carousel | Query về how-to, entertainment | "cách nấu phở" |
Featured Snippet | Query có câu trả lời ngắn | "thủ đô việt nam là gì" |
People Also Ask | Hầu hết query | (xuất hiện dạng accordion) |
Knowledge Panel | Entity được Google biết | "vinfast", "Hồ Chí Minh" |
Shopping Results | Query về sản phẩm | "iphone 16 giá" |
AI Overview | Query phức tạp | "so sánh iPhone vs Samsung" |
News | Query về sự kiện | "tin tức bóng đá hôm nay" |
→ Hiểu được điều này, bạn sẽ biết target search feature nào cho từ khóa của mình.
5.5. Trang đã được index nhưng KHÔNG xuất hiện trong kết quả — Tại sao?
Đây là tình huống nhiều người gặp:
"Search Console báo trang đã được index, nhưng tôi không thấy nó trong kết quả search. Tại sao?"
Google đưa ra 3 lý do chính:
Lý do 1: Nội dung không liên quan đến query của user
Trang có thể nói về "máy giặt LG", nhưng user search "máy giặt Samsung" → Google không hiển thị trang của bạn vì nó không liên quan.
→ Giải pháp: Đảm bảo content match với search intent. Dùng keyword research để biết user search gì.
Lý do 2: Chất lượng nội dung thấp
Trang được index nhưng chất lượng kém → Google đẩy xuống tận trang 10, 20 → không ai thấy.
→ Giải pháp: Cải thiện E-E-A-T, làm nội dung sâu hơn, độc đáo hơn.
Lý do 3: Robots meta rules ngăn serving
Có thể trang dùng noimageindex, nosnippet, hoặc các rule khác làm trang không hiển thị đầy đủ.
→ Giải pháp: Review meta tags.
Phần 6: 3 giai đoạn — Tổng hợp checklist cho mỗi giai đoạn
Tấn Phát Digital tổng hợp checklist debug cho mỗi giai đoạn:
Giai đoạn 1: CRAWLING — Trang có được crawl không?
Cách kiểm tra:
[ ] URL Inspection Tool trong Search Console — check "Crawl" status
[ ] Server logs — Googlebot có visit không?
[ ] Crawl Stats trong Search Console
Nếu KHÔNG crawl:
[ ] Check robots.txt — có disallow không?
[ ] Check server status — có lỗi 5xx không?
[ ] Check DNS — domain có resolve được không?
[ ] Check internal links — có link đến trang không?
[ ] Submit sitemap — đã add trang vào sitemap chưa?
[ ] Manual submit — dùng URL Inspection "Request indexing"
Giai đoạn 2: INDEXING — Trang có được index không?
Cách kiểm tra:
[ ] Search
site:yoursite.com/url-cu-thetrên Google[ ] URL Inspection Tool — check "Indexing" status
[ ] Page Indexing report trong Search Console
Nếu KHÔNG index:
[ ] Check meta robots — có noindex không?
[ ] Check canonical — có trỏ đến URL khác không?
[ ] Check content quality — có thin content không?
[ ] Check duplicate — có giống trang nào khác không?
[ ] Check rendering — JavaScript có lỗi không? (Test live URL → Screenshot)
[ ] Wait — đôi khi cần thời gian (vài giờ đến vài tuần)
Giai đoạn 3: SERVING — Trang có hiển thị cho user không?
Cách kiểm tra:
[ ] Search keyword cụ thể trên Google (incognito mode)
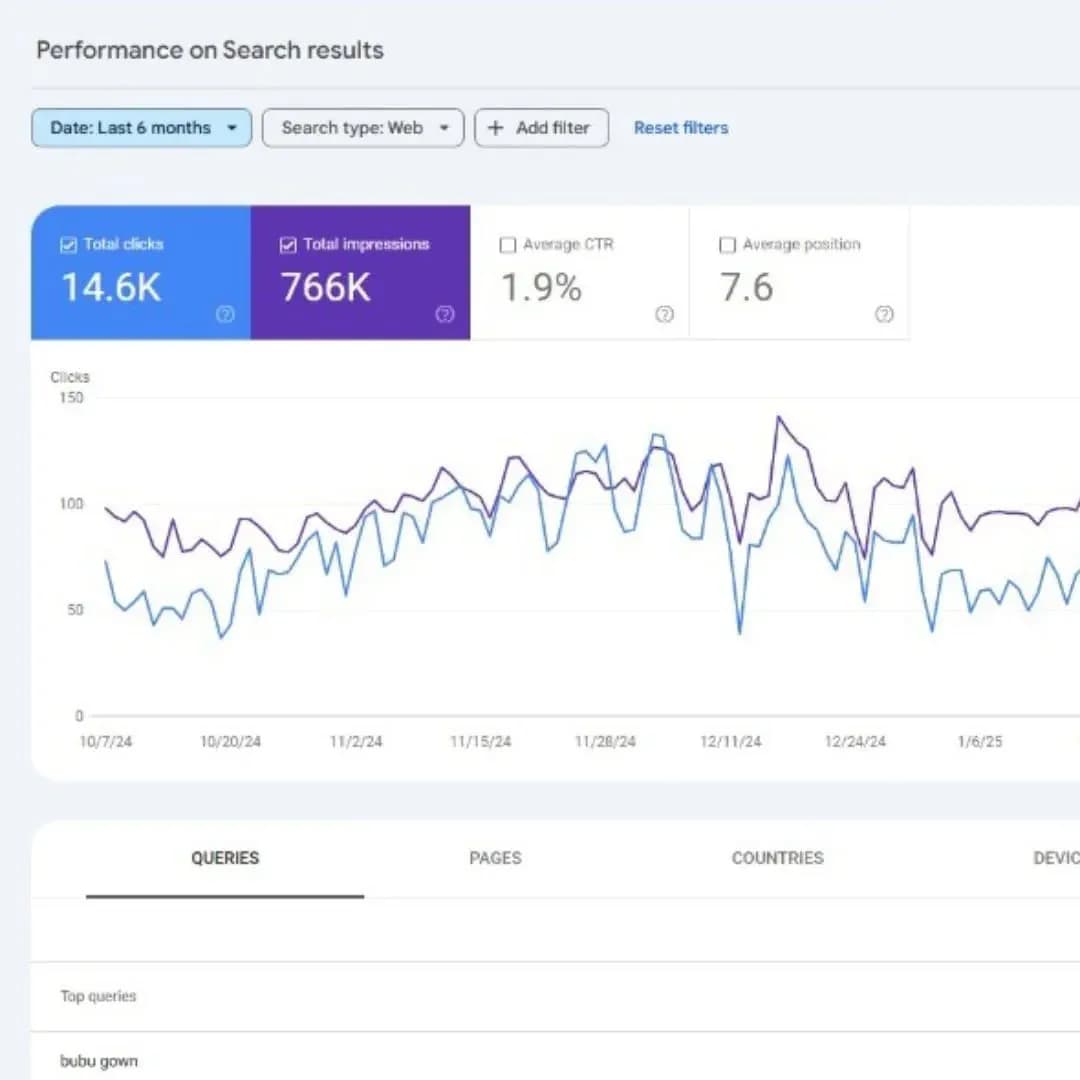
[ ] Performance report trong Search Console
[ ] Position tracking tools (Ahrefs, SEMrush)
Nếu KHÔNG serve hoặc rank thấp:
[ ] Check content quality — có đủ sâu, đủ giá trị không?
[ ] Check search intent — content có match với intent của query không?
[ ] Check E-E-A-T — có Experience, Expertise, Authoritativeness, Trustworthiness?
[ ] Check Page Experience — Core Web Vitals, mobile-friendly?
[ ] Check backlinks — có authority signals không?
[ ] Check competitors — đối thủ làm tốt hơn ở điểm gì?
Phần 7: Cách áp dụng kiến thức này vào chiến lược SEO
Hiểu 3 giai đoạn, bạn sẽ có chiến lược SEO logic hơn:
Cấp độ 1: Tối ưu cho CRAWLING
Mục tiêu: Đảm bảo Google truy cập được mọi trang quan trọng.
Hành động:
Cấu trúc URL rõ ràng — Dễ hiểu, có ý nghĩa
Internal linking mạnh mẽ — Mọi trang có link nội bộ trỏ đến
XML Sitemap — Khai báo các trang cho Google
robots.txt sạch sẽ — Không vô tình chặn
Server stable — Không xuống, không lỗi 5xx
Tốc độ tải nhanh — Tối ưu crawl budget
Loại bỏ orphan pages — Không để trang "mồ côi"
Cấp độ 2: Tối ưu cho INDEXING
Mục tiêu: Đảm bảo Google hiểu được và lưu trữ nội dung của bạn.
Hành động:
Title độc đáo, mô tả — Mỗi trang một title riêng
Meta description hấp dẫn — Tăng CTR
Semantic HTML — H1, H2, sections rõ ràng
Alt text cho hình ảnh — Google hiểu hình ảnh
Canonical tags chính xác — Tránh duplicate
Structured data — Giúp Google hiểu sâu hơn
Hreflang (nếu đa ngôn ngữ) — Khai báo phiên bản
Content chất lượng cao — Đáng để index
Cấp độ 3: Tối ưu cho SERVING
Mục tiêu: Đảm bảo Google chọn hiển thị trang của bạn cho các query liên quan.
Hành động:
Match search intent — Content giải quyết đúng nhu cầu
E-E-A-T cao — Experience, Expertise, Authoritativeness, Trustworthiness
Helpful content — Hữu ích thực sự cho user
Page experience tốt — Core Web Vitals, mobile-friendly, HTTPS
Backlinks chất lượng — Authority signals
Brand signals — Người dùng tìm thương hiệu bạn
Click-through rate cao — Title hấp dẫn, snippet tốt
Engagement signals — Dwell time, low bounce rate
Phần 8: Những hiểu lầm phổ biến về cách Google hoạt động
Hiểu lầm 1: "Submit website cho Google là cần thiết"
❌ Sai. Google tự tìm trang nếu có link dẫn đến.
✅ Đúng: Submit sitemap giúp Google tìm nhanh hơn nhưng không bắt buộc.
Hiểu lầm 2: "Trang được crawl = được index"
❌ Sai. Đây là 2 giai đoạn hoàn toàn riêng biệt.
✅ Đúng: Trang có thể được crawl nhưng KHÔNG được index nếu chất lượng kém.
Hiểu lầm 3: "Trang được index = sẽ hiển thị trên Google"
❌ Sai. Index chỉ là điều kiện cần, không phải điều kiện đủ.
✅ Đúng: Trang được index nhưng vẫn có thể không hiển thị cho user nếu không match query hoặc chất lượng thấp.
Hiểu lầm 4: "Càng nhiều trang được index càng tốt"
❌ Sai. Đây là tư duy sai lầm dẫn đến scaled content abuse.
✅ Đúng: Số ít trang chất lượng cao > Hàng nghìn trang chất lượng thấp.
Hiểu lầm 5: "Google sẽ rank cao nếu tôi nhồi nhiều từ khóa"
❌ Sai. Đây là tư duy SEO của 2010, đã lỗi thời từ lâu.
✅ Đúng: Google hiểu được semantic meaning, không chỉ keyword density.
Hiểu lầm 6: "Tôi có thể trả tiền cho Google để rank cao hơn"
❌ Sai. Google nhấn mạnh 2 lần trong tài liệu chính thức: KHÔNG nhận tiền cho ranking.
✅ Đúng: Google Ads là quảng cáo — không liên quan đến organic ranking.
Hiểu lầm 7: "Trang load nhanh = chắc chắn rank cao"
❌ Sai. Tốc độ là một trong hàng trăm yếu tố.
✅ Đúng: Tốc độ ảnh hưởng đến crawl budget và UX, nhưng nội dung chất lượng vẫn là yếu tố quan trọng nhất.
Phần 9: FAQ — Câu hỏi thường gặp
Q1: Bao lâu Google sẽ crawl trang mới của tôi?
Trả lời: Tùy thuộc nhiều yếu tố:
Website mới: vài tuần đến vài tháng
Website đã có authority: vài giờ đến vài ngày
Website rất uy tín (news site): trong vài phút
Để tăng tốc:
Submit qua URL Inspection Tool
Cập nhật sitemap
Build internal link đến trang mới
Q2: Tại sao trang của tôi bị index nhưng không hiển thị trên Google?
Trả lời: Xem Phần 5.5 ở trên. 3 lý do chính:
Content không match query
Chất lượng thấp
Meta rules ngăn serving
Q3: Google có index PDF, hình ảnh, video không?
Trả lời: Có. Google index nhiều loại file:
HTML
PDF, DOC, XLSX, PPT
Hình ảnh (JPEG, PNG, WebP, AVIF, SVG)
Video (MP4, WebM)
Text files
Q4: Tôi có thể yêu cầu Google KHÔNG crawl một số trang không?
Trả lời: Có. Dùng:
robots.txtDisallow — chặn crawlMeta
noindex— cho phép crawl nhưng không indexHTTP Auth — yêu cầu đăng nhập
Q5: Google update bao lâu một lần?
Trả lời:
Index update: Liên tục 24/7
Core algorithm updates: Vài lần/năm (lớn) + hàng trăm thay đổi nhỏ
Spam updates: Vài lần/năm
Specific updates (helpful content, product reviews, v.v.): Khi cần
Theo dõi tại Google Search Status Dashboard.
Q6: Tại sao đối thủ rank cao hơn tôi dù site họ chất lượng kém hơn?
Trả lời: Có thể vì:
Họ có backlinks mạnh hơn
Site họ có authority lâu năm
Họ match search intent tốt hơn (dù nội dung không hay)
Họ có brand signals mạnh hơn
Tạm thời họ rank cao, sẽ bị xuống ở update tiếp theo
→ Đừng so sánh từng yếu tố. Tập trung làm tốt mọi yếu tố.
Q7: Google sử dụng AI để rank không?
Trả lời: Có. Google sử dụng nhiều AI systems:
RankBrain — Hiểu query
BERT — Hiểu ngữ cảnh ngôn ngữ
MUM — Multitask Unified Model
Helpful Content System — Đánh giá nội dung hữu ích
AI Overviews — Tạo phản hồi AI
→ Nhưng vẫn xoay quanh content chất lượng.
Q8: Algorithm của Google có công khai không?
Trả lời: KHÔNG. Google không công khai algorithm cụ thể vì:
Tránh bị spam khai thác
Quá phức tạp (hàng trăm yếu tố)
Liên tục thay đổi
Nhưng Google công khai nguyên tắc và best practices — đó là tài liệu chúng ta đang đọc.
Phần 10: Bài học rút ra cho doanh nghiệp Việt Nam
Bài học 1: SEO không phải là "thủ thuật" — Đó là tuân thủ cơ chế
Hiểu 3 giai đoạn của Google, bạn nhận ra: không có shortcut. Bạn chỉ có thể:
Giúp Google crawl dễ dàng
Giúp Google hiểu nội dung
Tạo lý do để Google chọn hiển thị bạn
Bài học 2: Mỗi vấn đề SEO có 1 giai đoạn cụ thể
Khi gặp vấn đề, đừng hoảng. Hãy xác định:
Crawling issue → Server, robots.txt, internal links
Indexing issue → Content quality, canonical, meta tags
Serving issue → Relevancy, authority, user experience
→ Giải pháp sẽ khác nhau cho mỗi giai đoạn.
Bài học 3: Đầu tư đúng nơi
Đừng tiêu tiền vào:
"Đẩy top" bằng black hat
"Mối quan hệ đặc biệt với Google"
"Submit website" hàng loạt
"Tools tự động tăng traffic"
Hãy đầu tư vào:
Server và technical setup (Crawling)
Content và structure (Indexing)
Brand và authority (Serving)
Bài học 4: Kiên nhẫn
Google nói rất nhiều lần: SEO cần thời gian (4-12 tháng). Đó là vì:
Crawl mới → cần vài ngày đến vài tuần
Index → cần thêm vài ngày đến vài tuần
Build trust và authority → cần vài tháng đến vài năm
→ Đừng tin các cam kết "top 1 trong 30 ngày" — bất khả thi với SEO chân chính.
Bài học 5: Học từ nguồn chính thức
Bài viết này dịch từ tài liệu chính thức của Google. Đó là nguồn đáng tin nhất.
Đừng học SEO từ:
Các video YouTube cá nhân không có background
Group Facebook "SEO Việt Nam" toàn thông tin cũ
"Khóa học SEO 999k" hứa hẹn quá mức
Hãy học từ:
Google Search Central (developers.google.com/search)
Google Search Central Blog
Search Off the Record podcast
Các agency uy tín với case study thật
Hiểu Google = Làm SEO tốt
Sau khi đọc hết bài viết này, bạn đã hiểu được cơ chế cốt lõi mà Google Search sử dụng. Đây là kiến thức nền tảng mà mọi người làm SEO cần nắm vững.
3 thông điệp cuối cùng
1. Google Search là một hệ thống tự động phức tạp. Nó không bị thao túng bởi tiền, mối quan hệ, hay "thủ thuật" đơn giản. Nó chỉ "tin" vào dữ liệu thật và chất lượng thật.
2. 3 giai đoạn — Crawling, Indexing, Serving — là khung tư duy. Mọi vấn đề SEO đều rơi vào một trong ba giai đoạn này. Khi gặp vấn đề, hãy hỏi: "Vấn đề của tôi ở giai đoạn nào?"
3. SEO là nghệ thuật giúp Google hiểu và tin tưởng bạn. Bạn không "chiến đấu" với Google — bạn hợp tác với nó. Khi mục tiêu của bạn (tạo nội dung hữu ích cho user) trùng với mục tiêu của Google (cung cấp kết quả tốt nhất), bạn sẽ thành công.
Lời nhắn từ Tấn Phát Digital
Nếu bạn đã đọc đến đây, bạn đã có kiến thức tốt hơn 90% người làm SEO ở Việt Nam. Hãy:
Bookmark bài viết này để tham khảo khi cần
Áp dụng vào website của mình ngay
Chia sẻ với team để mọi người cùng hiểu
Tiếp tục học — SEO luôn thay đổi
Và quan trọng nhất: đừng tin bất kỳ ai nói SEO là "magic". Đó là science — khoa học có nguyên tắc rõ ràng. Hiểu nguyên tắc → bạn làm chủ được kết quả.
Tài liệu tham khảo chính thức
In-depth guide to how Google Search works — Tài liệu nguồn
Công cụ kiểm tra 3 giai đoạn
Giai đoạn | Công cụ |
|---|---|
Crawling | Search Console Crawl Stats, Server logs, URL Inspection |
Indexing | site: operator, Page Indexing report, URL Inspection |
Serving | Search Console Performance report, manual SERP check |
Về Tấn Phát Digital
Tấn Phát Digital giúp doanh nghiệp Việt Nam hiểu sâu về SEO — không chỉ làm theo "công thức" mà còn nắm vững nguyên lý. Chúng tôi tin rằng: khi bạn hiểu được tại sao, bạn sẽ làm đúng được mãi mãi.
Dịch vụ liên quan
SEO Foundation Audit — Đánh giá 3 giai đoạn Crawling, Indexing, Serving
Crawl Optimization — Tối ưu khả năng crawl của Googlebot
Index Issues Resolution — Giải quyết các vấn đề indexing
SERP Visibility Improvement — Tăng khả năng hiển thị trong kết quả tìm kiếm
SEO Workshop — Đào tạo team in-house hiểu cách Google hoạt động
SEO Consulting theo giờ — Tư vấn theo nhu cầu cụ thể
Bạn đang gặp vấn đề "trang không index" hoặc "không xuất hiện trên Google"? Liên hệ Tấn Phát Digital để được audit và xác định chính xác vấn đề thuộc giai đoạn nào — từ đó có giải pháp đúng.
Bài viết được biên soạn và phân tích từ tài liệu chính thức của Google Search Central, cập nhật ngày 18/12/2025. Bản quyền nội dung gốc thuộc về Google (CC BY 4.0). Phần phân tích chuyên sâu, ví dụ Việt hóa, FAQ, hiểu lầm phổ biến và checklist debug thuộc về Tấn Phát Digital.
Hiểu cách Google Search hoạt động là bước đầu tiên để xây dựng chiến lược SEO hiệu quả và bền vững.
Nếu doanh nghiệp của bạn cần tối ưu website chuẩn Technical SEO và AI Search, hãy liên hệ Tấn Phát Digital để được tư vấn.