Sự hiện diện của nội dung trên Google không đơn thuần là hệ quả của việc xuất bản mà là kết quả của một quy trình kỹ thuật phức tạp bao gồm các giai đoạn khám phá, thu thập dữ liệu và xử lý thuật toán. Trong bối cảnh số lượng nội dung số bùng nổ, Tấn Phát Digital nhận thấy Google đã trở nên khắt khe hơn trong việc lựa chọn những gì xứng đáng được lưu trữ trong chỉ mục của mình. Đối với các nhà quản trị website và chuyên gia SEO, việc xác định các bài viết chưa được lập chỉ mục (index) là nhiệm vụ ưu tiên hàng đầu, bởi một trang web không nằm trong chỉ mục đồng nghĩa với việc nó hoàn toàn vô hình trước người dùng tiềm năng. Quá trình này đòi hỏi một hệ thống kiểm tra đa tầng, từ các thao tác thủ công đơn giản đến việc ứng dụng các giao diện lập trình ứng dụng (API) và phân tích nhật ký máy chủ để tìm ra những rào cản vô hình đang ngăn chặn dòng chảy của dữ liệu.
Hệ thống phương pháp luận xác định trạng thái lập chỉ mục
Để trả lời câu hỏi về việc kiểm tra các bài viết chưa được index, Tấn Phát Digital khuyến nghị tiếp cận theo một phân cấp từ vi mô đến vĩ mô, sử dụng các công cụ chính thống phối hợp với các giải pháp phân tích dữ liệu lớn.
Kỹ thuật truy vấn trực tiếp bằng toán tử tìm kiếm
Toán tử site: là công cụ cổ điển nhưng vẫn mang lại giá trị chẩn đoán tức thời. Bằng cách sử dụng cú pháp site:yourdomain.com/url-bai-viet, bạn có thể nhận được phản hồi ngay lập tức về trạng thái ghi nhận của Google. Dưới đây là các kỹ thuật phổ biến:
Kiểm tra toàn miền (Ví dụ:
site:sapo.vn): Giúp ước tính tổng số trang đã được Google lập chỉ mục trên toàn bộ website.Kiểm tra URL cụ thể (Ví dụ:
site:sapo.vn/abc-la-gi): Xác minh chính xác trạng thái index của một bài viết duy nhất.Kiểm tra thư mục (Ví dụ:
site:domain.com/blog/): Đánh giá độ bao phủ của Google trong một phân mục cụ thể như chuyên mục tin tức hoặc blog.
Giới chuyên gia tại Tấn Phát Digital lưu ý rằng kết quả từ toán tử site: là một con số ước tính và có thể có độ trễ đồng bộ hóa giữa các máy chủ. Vì vậy, đây chỉ nên được coi là bước sàng lọc ban đầu.
Khai thác sức mạnh của Google Search Console
Google Search Console (GSC) cung cấp dữ liệu chính xác nhất vì nó truy xuất trực tiếp từ cơ sở dữ liệu nội bộ của Google. Công cụ "Kiểm tra URL" là tiêu chuẩn để xác định lý do tại sao một bài viết chưa được index. Khi nhập một URL, hệ thống sẽ trả về trạng thái chi tiết: "URL nằm trên Google" hoặc "URL không nằm trên Google".
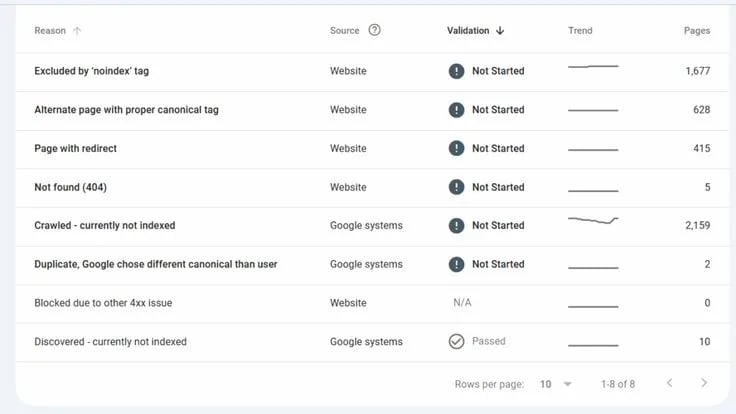
Một khía cạnh quan trọng là báo cáo "Trang" trong phần "Lập chỉ mục". Tại đây, Google phân loại rõ ràng các lý do khiến bài viết bị loại trừ. Phân tích biểu đồ này cho phép đội ngũ kỹ thuật của Tấn Phát Digital nhận diện các lỗi hệ thống thay vì chỉ kiểm tra từng bài viết đơn lẻ.
Kiểm toán lập chỉ mục hàng loạt (Bulk Index Checking)
Đối với các website lớn, việc kiểm tra thủ công là bất khả thi. Các giải pháp kiểm tra hàng loạt đã trở thành một phần thiết yếu trong quy trình vận hành SEO hiện đại:
Sử dụng công cụ chuyên dụng: Screaming Frog SEO Spider, JetOctopus hoặc Sitechecker cho phép tích hợp API của GSC để đối soát trạng thái index của toàn bộ danh sách URL trong sitemap.
Phát hiện trang mồ côi: Quy trình này giúp tìm ra những trang có tồn tại nhưng không có liên kết nội bộ trỏ tới, khiến Googlebot khó tìm thấy hoặc không ưu tiên lập chỉ mục.
Phân tích chuyên sâu các trạng thái không lập chỉ mục
Việc hiểu rõ thuật ngữ của Google là chìa khóa để Tấn Phát Digital đưa ra các biện pháp khắc phục chính xác.
Danh mục các trạng thái lập chỉ mục phổ biến
Đã khám phá - Hiện chưa được lập chỉ mục (Discovered - currently not indexed): Google đã biết đến URL (qua sitemap hoặc link trỏ về) nhưng chưa truy cập để đọc nội dung. Nguyên nhân thường do ngân sách thu thập dữ liệu thấp hoặc máy chủ yếu. Giải pháp là tăng cường liên kết nội bộ và tối ưu tốc độ phản hồi máy chủ.
Đã thu thập dữ liệu - Hiện chưa được lập chỉ mục (Crawled - currently not indexed): Googlebot đã ghé thăm và tải nội dung nhưng quyết định không lưu trữ vào chỉ mục. Nguyên nhân thường do nội dung mỏng, trùng lặp hoặc thiếu giá trị. Cần nâng cấp chất lượng nội dung và kiểm tra lại thẻ Canonical.
Bị chặn bởi lệnh 'noindex' (URL marked 'noindex'): Bài viết bị chặn trực tiếp trong mã nguồn hoặc cấu hình plugin SEO. Cần kiểm tra lại mã HTML và gỡ bỏ thẻ noindex ở các trang quan trọng.
Lỗi Soft 404: Trang hiển thị nội dung lỗi hoặc trống nhưng vẫn trả về mã trạng thái 200 thành công. Cần bổ sung nội dung hoặc chuyển hướng 301 về trang phù hợp.
Các rào cản kỹ thuật và hạ tầng
Bên cạnh nội dung, một loạt lỗi kỹ thuật có thể khiến bài viết "tàng hình" trước Googlebot.
Sai sót trong tệp cấu hình Robots.txt và.htaccess
Tệp robots.txt là hướng dẫn đầu tiên bot đọc khi truy cập. Một lỗi như Disallow: / có thể chặn toàn bộ website. Tấn Phát Digital khuyến nghị kiểm tra định kỳ tệp này để đảm bảo không chặn nhầm thư mục quan trọng. Ngoài ra, cấu hình máy chủ hoặc tường lửa đôi khi nhận nhầm Googlebot là tấn công DDoS và chặn truy cập (lỗi 403), dẫn đến gián đoạn lập chỉ mục.
Mobile-First Indexing và Trải nghiệm trang
Google ưu tiên phiên bản di động để đánh giá website. Nếu bài viết bị lỗi hiển thị trên mobile (chữ quá nhỏ, tràn khung), Google có thể từ chối index. Tối ưu hóa các chỉ số Core Web Vitals như LCP và CLS không chỉ giúp xếp hạng tốt hơn mà còn giúp Googlebot truy cập website thường xuyên hơn.
Chiến lược ứng dụng API và Tự động hóa
Đối với SEO kỹ thuật, tự động hóa là phương pháp hiệu quả nhất để kiểm soát tình trạng index ở quy mô lớn.
Tự động hóa bằng Google Sheets và Apps Script
Một giải pháp sáng tạo là sử dụng Google Sheets kết hợp với Apps Script để tạo trình kiểm tra index tùy chỉnh. Bằng cách sử dụng API của các dịch vụ như Serper.dev, quản trị viên có thể kiểm tra hàng nghìn URL tự động mỗi tháng và nhận cảnh báo khi bài viết bị rớt khỏi chỉ mục.
Khai thác Google Indexing API
Đây là công cụ mạnh mẽ để thông báo cho Google về các trang mới hoặc thay đổi ngay lập tức.
So sánh Sitemap và Indexing API:
Cơ chế: Sitemap là phương thức thụ động (Google tự quét khi có thời gian), Indexing API là phương thức chủ động (gửi tín hiệu "đẩy" nội dung).
Độ trễ: Sitemap có thể mất vài ngày; Indexing API thường được xử lý trong vòng 24 giờ.
Giới hạn: Sitemap không giới hạn URL; Indexing API mặc định giới hạn khoảng 200 yêu cầu/ngày.
Độ tin cậy: Sitemap là tiêu chuẩn cho mọi web; Indexing API có hiệu quả nhất với dữ liệu tuyển dụng hoặc sự kiện trực tiếp.
Quản trị Ngân sách thu thập dữ liệu (Crawl Budget)
Tại Tấn Phát Digital, chúng tôi luôn chú trọng tối ưu ngân sách thu thập dữ liệu cho website doanh nghiệp để đảm bảo tài nguyên của Googlebot được dùng cho các trang giá trị nhất.
Chiến lược tối ưu hóa Crawl Budget
Xử lý chuỗi chuyển hướng (Redirect Chains): Đảm bảo liên kết nội bộ trỏ trực tiếp đến URL đích cuối cùng để tiết kiệm tài nguyên bot.
Loại bỏ nội dung trùng lặp: Sử dụng thẻ Canonical triệt để.
Phân tích nhật ký máy chủ (Log File Analysis): Sử dụng các công cụ như Botify để hiểu hành vi thực tế của bot trên trang và phát hiện các "bẫy thu thập dữ liệu".
Lộ trình hành động
Việc kiểm tra bài viết chưa được index là một quy trình tỉ mỉ. Tấn Phát Digital đề xuất lộ trình hành động sau:
Thiết lập hệ thống giám sát định kỳ qua GSC và các công cụ tự động hóa.
Tối ưu chất lượng nội dung theo tiêu chuẩn E-E-A-T để tránh bị từ chối index sau khi thu thập.
Củng cố hạ tầng kỹ thuật, đảm bảo tốc độ tải và tính thân thiện với thiết bị di động.
Cuối cùng, lập chỉ mục là một cuộc chơi về niềm tin. Khi Google tin rằng website của bạn cung cấp giá trị thực sự, quy trình này sẽ diễn ra tự nhiên và nhanh chóng. Hãy cùng Tấn Phát Digital xây dựng một nền tảng SEO vững chắc từ những chi tiết kỹ thuật nhỏ nhất.